Savvy Silicon: How I Made a Crossword Puzzle Helper With AI
 Matt Butcher
Matt Butcher
crossword
puzzle
ai
fermyon cloud
serverless ai

Recently, I began working on crossword puzzles, and I have developed an annoying habit. When anyone is around me, I begin to read them clues and ask them questions such as, “The clue is ‘pinkish’; what are the different shades of pink?” or “Who else, besides Matt Damon, was in ‘The Bourne Identity’?”
The fun part of doing a crossword puzzle is having to combine wordplay, general knowledge, and vocabulary to solve items one by one. It would be boring to, merely, have someone tell me all the answers, but sometimes I need a little help. And rather than irritate my family by asking them such questions, I decided to take a shot at doing this using generative AI.
Clue: “Text-based AI tools” (4 letters)
Answer: LLMs
A chat-oriented LLM (Large Language Model) is perfect for the task at hand. The crossword puzzles I like to do are general knowledge ones, like the New York Times or the Apple News+ versions. The puzzle solver is expected to know things ranging from history to the arts to sports to pop culture. Today’s popular LLMs are trained on general knowledge data sources. So they should be well equipped to handle this sort of work.
Now, I don’t necessarily want to have the LLM solve the puzzle for me (which is good because that is actually quite hard to do). Instead, I want it to be an assistant that I can brainstorm with as I work my way through the puzzle.
Fermyon Cloud has LLaMa2-Chat built-in, and it uses the 13-billion parameter version, which should be just right for the task at hand. In Fermyon Cloud, an answer will take a second or two.
While developing locally, though, I’ll use the 7-billion parameter version of LLaMa2-Chat. That’s still slow when running locally, but on my machine (a 2021 MPB), I get answers in around a minute. That’s acceptable during development.
Clue: “Turn, or a Wasm development tool” (4 letters)
Answer: Spin
To build the application, I used Spin and TypeScript. The full project is available on GitHub. I’m not going to go through the entire application line-by-line, but I’ll highlight the general architecture, and then we’ll focus on just the LLM inferencing code.
- Instructions at the end of this article allow you to deploy the full crossword-helper project directly to Fermyon Cloud using Serverless AI (eliminating the need to download models). Meanwhile, continue reading to learn how I developed the crossword-helper.
To get started, I created a new application using the following commands:
# Using the latest TypeScript/Javascript SDK
$ spin templates install --git https://github.com/fermyon/spin-js-sdk --upgrade
# Creating the application using the spin new command
$ spin new http-ts crossword-helper --accept-defaults
The spin new command scaffolded out the main parts of the application for me:
# Changing into the application's directory
$ cd crossword-helper
# Inspecting the application's initial layout
$ tree .
.
├── package.json
├── README.md
├── spin.toml
├── src
│ └── index.ts
├── tsconfig.json
└── webpack.config.js
I’ll dive into the TypeScript code in a moment. But first, let’s take a higher-level look at what we’re trying to build.
The application needs two parts:
- An HTML front end with a few bits of JavaScript. This is the part where I’ll ask the questions.
- An API that takes a question as input and returns a JSON-formatted version of the LLM’s answer (back to the above HTML client) as a result.
As this translates into a Spin application, that means we need two components. The first was scaffolded out by the spin new command above.
The second component I need is a file server to serve out my HTML front-end. Fortunately, Spin can add the Spin fileserver template to an existing application using the spin add command:
# Ensure Spin templates are installed (and up to date)
$ spin templates install --git https://github.com/fermyon/spin --upgrade
# Add a static fileserver component to the application
$ spin add static-fileserver --accept-defaults
Enter a name for your new component: fileserver
At this point, we can see two separate components in our application’s manifest (the spin.toml) file. And because I am using AI inferencing with llama2-chat, I need to make one further modification to the manifest:
spin_manifest_version = "1"
authors = ["Matt Butcher <matt.butcher@fermyon.com>"]
description = ""
name = "crossword-helper"
trigger = { type = "http", base = "/" }
version = "0.1.0"
# This is our function
[[component]]
id = "crossword-helper"
source = "target/crossword-helper.wasm"
exclude_files = ["**/node_modules"]
ai_models = ["llama2-chat"] # <--- Add suport for llama2-chat
[component.trigger]
route = "/api/question"
[component.build]
command = "npm run build"
# This serves the static files (HTML, CSS, etc.)
# And it was generated by `spin templates install static-fileserver`
[[component]]
source = { url = "https://github.com/fermyon/spin-fileserver/releases/download/v0.0.3/spin_static_fs.wasm", digest = "sha256:38bf971900228222f7f6b2ccee5051f399adca58d71692cdfdea98997965fd0d" }
id = "fileserver"
files = [{ source = "assets", destination = "/" }]
[component.trigger]
route = "/..."
That’s all of the scaffolding and configuration done, so let’s move on.
Clue: “Looks, but doesn’t purchase” (7 letters)
Answer: Browser
I want a simple user interface that lets me enter a question, and then wait for the AI to answer.
I’m not going to walk through the HTML or client-side JavaScript. It’s quite basic, and it’s right here if you’d like to look at the code. But here’s a screenshot of the application when I run spin up .
When I type in a question and click on the “Get a Hint” button, the HTML client will send a POST request to the route (which we can see in the spin.toml above) called /api/question. When the crossword-helper component runs, it will return a result, which the client-side JS will display in my browser.
Here’s an example of what it looks like when I ask a question and wait for the answer:
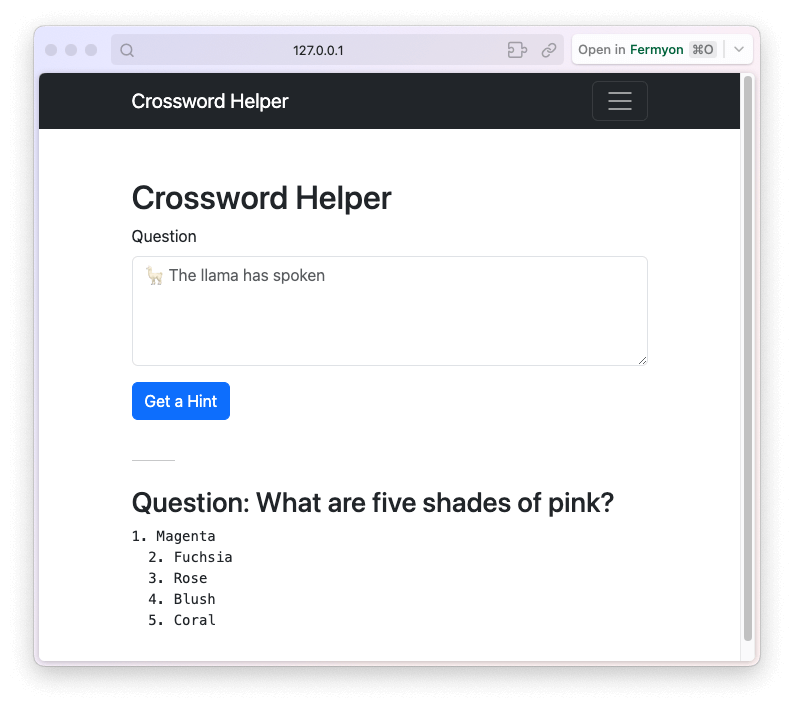
It answered my question, “What are five shades of pink?” with a list of five shades of pink! That’s great. Running that inference locally took me about 90 seconds. When we later deploy to Fermyon Cloud, that time will go way down.
Next, let’s look at the main handler function.
Clue: “A good night’s _____” (4 letters)
Answer: Rest
Now, we will look at the handler that takes the question, runs the LLM inference, and then returns the answer:
import { Llm, InferencingModels, HandleRequest, HttpRequest, HttpResponse } from "@fermyon/spin-sdk"
const decoder = new TextDecoder()
const model = InferencingModels.Llama2Chat
export const handleRequest: HandleRequest = async function (request: HttpRequest): Promise<HttpResponse> {
// Get the data posted from the web browser
let question = decoder.decode(request.body);
// Ask the LLM a question
let res = Llm.infer(model, ask(question), { maxTokens: 250 })
// Send the entire response back to the user
return {
status: 200,
headers: { "content-type": "application/json" },
body: JSON.stringify(res)
}
}
Since Spin is a serverless framework, we don’t need to set up a server process. Instead, we just need to implement the handleRequest() function, which will be called each time this API’s URL endpoint gets a request.
The HTML form initiates the submission of a request object, containing the question data, to the server using the HTTP POST method. This request, represented as form data, comprises key-value pairs that undergo encoding for transmission. To effectively handle this request, it becomes necessary to extract the data from the request body. Given that the data resides in an encoded format within the request body, we employ a TextDecoder to decode it.
Next, we have the most important line in the application:
let res = Llm.infer(model, ask(question), { maxTokens: 250 })
This runs the inference. We pass it the model we want to use (Llama2Chat), the question we are going to ask, and also a configuration object. I’m using the configuration object to tell the LLM not to return more than 250 tokens (around 200 words).
In a moment, we’ll look at the function ask(), which is called on that line. But for now, we can focus on the flow of handleRequest(). The Llm.infer() call returns a response, res.
The call to Llm.infer() will invoke the LLM to answer the question. And as we saw, this may take a minute or two to complete when run locally. The result it returns, though, will contain the answer that the LLM generated.
When running locally, you will need to consider Meta licenses and also install the models.
At the end of the function, we’re just encoding res into JSON and returning it in the response. From there, our front-end code will display the result from the LLM.
In our glance through the handleRequest() function, though, we skipped one of the most important parts: Building the prompt.
Clue: “Timely” (6 letters)
Answer: Prompt
In AI lingo, a prompt is the piece of text that we send to the LLM so it can run an inference. As we saw above, we want to ask the LLM a question. But there’s a little more to the prompt than just asking a question. We also need to provide system-level instructions that tell the LLM how to behave.
The process of creating a good prompt is called prompt engineering. And that’s what we’re going to do now. The ask() function constructs our prompt:
function ask(question: string): string {
return `
<s>[INST] <<SYS>>
Your are a bot that helps solve crossword puzzle clues.
Respond with one or more suggestions. A suggested answer should be less than 20 characters.
<</SYS>>
${question} [/INST]
`
}
The structure of the function is easy: We’re just formatting a string and returning it.
The content is a little more sophisticated. In a nutshell:
<s> marks the start of the conversation.[INST] denotes an interaction between us and the LLM. For example, if we were modelling a conversation, we might have several [INST] sections.<<SYS>> denotes a system directive. We use system directives to tell the LLM how it should behave.
With that in mind, above, we’ve basically done two things: Instead of a <<SYS>> directive, we’ve told the LLM that it’s a helpful crossword puzzle clue-giver. And after that, we’re adding our question. In TypeScript, the ${question} will be interpolated with the value of question. So if our question is “What are five shades of pink?” then the entire prompt will be:
<s>[INST] <<SYS>>
Your are a bot that helps solve crossword puzzle clues.
Respond with one or more suggestions. A suggested answer should be less than 20 characters.
<</SYS>>
What are five shades of pink? [/INST]
Backing up to the previous section, ask() is called inside of the call to Llm.infer(), so this prompt is sent on to the LLM, which then responds.
Running a spin build and then a spin up, we can give it another test locally, this time with a question about the cast of The Bourne Identity:
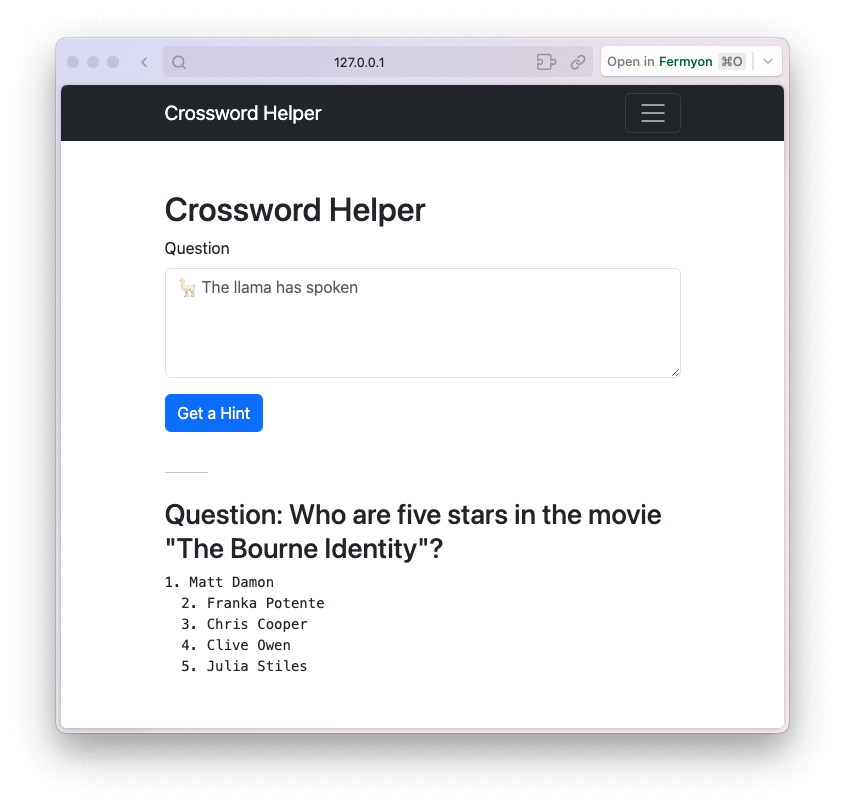
The answer it provided is correct and gives me a few more names I can try when answering that question about actors in the movie.
Clue: “Send to duty” (6 letters)
Answer: Deploy
Next, we’ll deploy this into Fermyon Cloud with the command spin deploy. This will package the application and push it to Fermyon’s free tier, where we can take advantage of AI-grade GPUs. When the deployment is complete, we can try out the application again, asking the same question about the Bourne Identity.
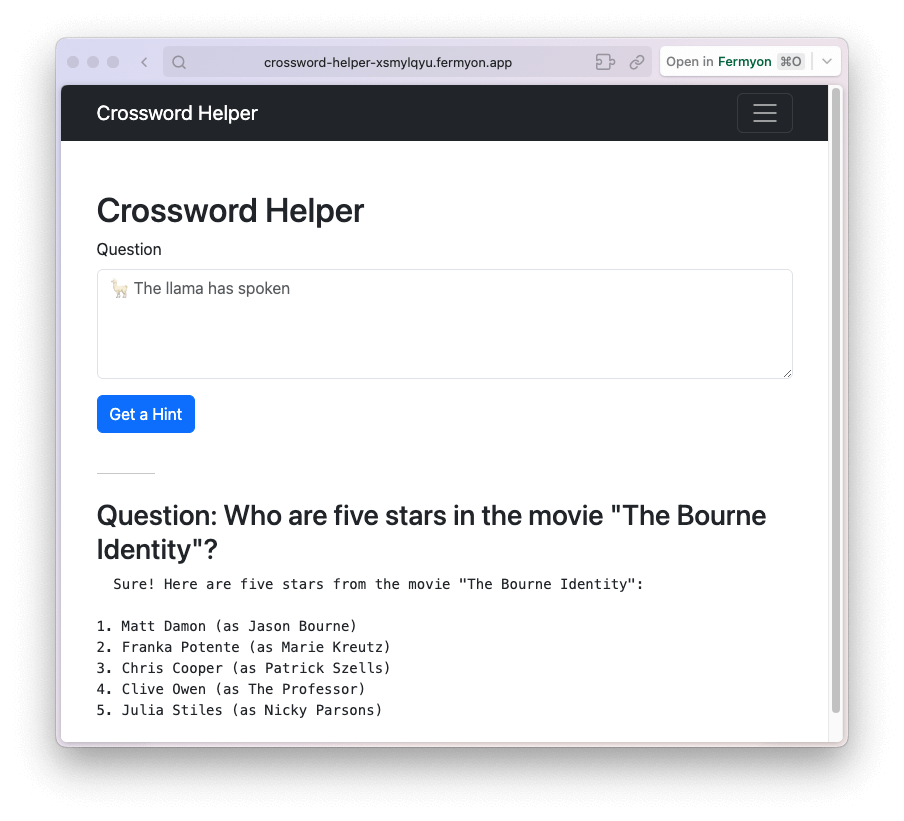
There are two things to note:
- I received an answer in about one second, so the AI-grade GPUs are definitely making things easier and faster.
- The answer I received was more detailed.
The reason for the increased detail is the model. I mentioned that when running locally, I used the 7-billion parameter LLaMa2-Chat model. Fermyon Cloud runs the 13-billion parameter version of that same model, so I get much better results.
In the testing we’ve seen here in this post, the answers to all of the questions were accurate and concise. However, if you play around with the 7- and 13-billion varieties of these two models, you will definitely notice the 13-billion parameter version is more accurate.
Clue: “Wrap up?” (10 letters)
Answer: Conclusion
The application presented here is pretty basic. As mentioned earlier, below are the steps to deploy my full crossword helper directly to Fermyon Cloud using Serverless AI, without downloading models. Sign up here for Serverless AI, then run the following:
git clone git@github.com:technosophos/crossword-helper.git
cd crossword-helper
npm install
npm run build
spin deploy
As far as the application goes as a whole, I have a plan to make it a little more sophisticated. First, I’d like to add the notion of a session, where the model remembers the previous questions so that I can gradually refine an answer during the course of solving a particular puzzle. But I’ve been using this application to help me for a few weeks, and it’s been helpful.
If you’d like to try your hand at building an AI-based application, head over to this Serverless AI tutorial. For inspiration and technical info, you can take a look at several examples in the Spin Up Hub.
And, as always, if you want to chat with human beings instead of an LLM, join our Discord! Just be aware that I might ask you to help me with my crossword puzzles!