Introducing Fermyon Serverless AI
 Radu Matei
Radu Matei
spin
wasm
webassembly
cloud
ai
serverless

Since we started Fermyon, we have been focused on building a computing platform to serve as the foundation for a new generation of serverless, and in the process we built Spin and Fermyon Cloud — the open source developer tool and the cloud platform for serverless WebAssembly.
Over the last few months, Artificial Intelligence (AI) has become one of the most popular workloads in computing. However, to inject AI capabilities into their applications, developers must use new tools, consider expensive hardware and cold starts, target specific platforms and architectures, or be locked into proprietary platforms.
Today we are introducing a new service in our cloud offering — Fermyon Serverless AI. This new set of features, extend what you can build with Fermyon Cloud and give you the building blocks to integrate AI capabilities in your serverless applications without worrying about assigning expensive GPUs to your applications, or about their frequent minute-long cold starts.
Using Fermyon Serverless AI, developers will be able to:
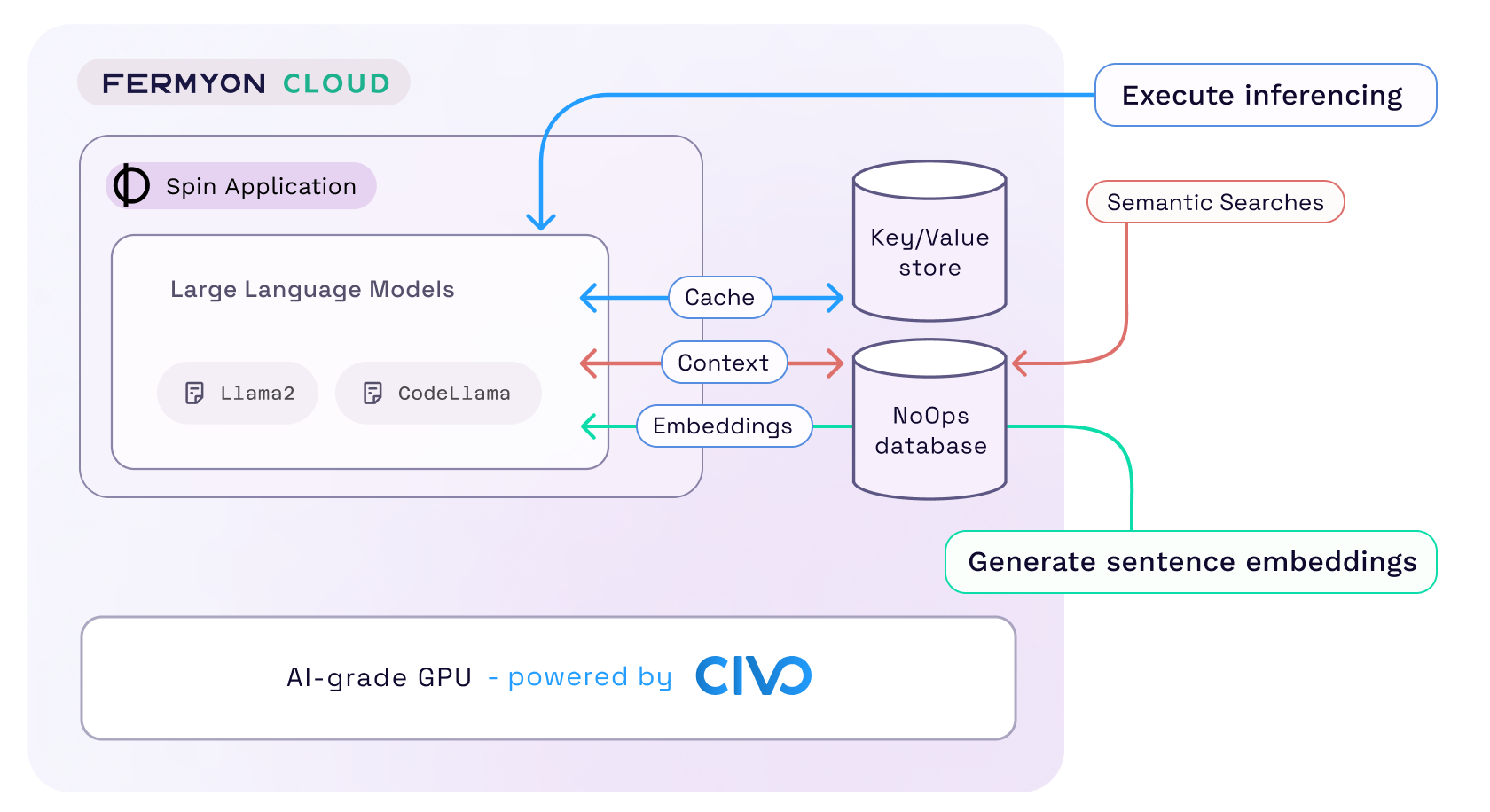
- execute inferencing on Large Language Models (LLMs) for Llama2 and CodeLlama models on state-of-the-art GPUs with no extra setup
- generate sentence embeddings for their data, then store, search, and retrieve it using a vector-ready database
- cache inferencing responses in a built-in key/value storage
- run entire full-stack serverless applications that can use configuration and secrets, custom domains, relational and non-relational data stores, or built-in observability.
Using WebAssembly to run workloads, we can assign a fraction of a GPU to a user application just in time to execute an AI operation. When the operation is complete, we assign that fraction of the GPU to another application from the queue. And because the startup time in Fermyon Cloud is milliseconds, that’s how fast we can switch between user applications that are assigned to a GPU. If all GPU fractions are busy crunching data, we queue the incoming application until the next one is available.
This has two big implications:
- users don’t have to wait for a virtual machine or container to start and for a GPU to be attached to it
- we can achieve significantly higher resource utilization and efficiency for our infrastructure
Efficiency and sustainability played a big factor in how we chose the infrastructure provider for Fermyon Serverless AI — we are delighted to work with Civo and use their new carbon-neutral GPU Compute Service just announced at Civo Navigate.
If you are interested in running AI workloads locally, we are also making these capabilities available in the Spin open source project! If you have a powerful workstation, you can generate embeddings and run inferencing on similar language models on your machine, simplifying the developer loop and giving you the ability to run your application anywhere Spin runs. We are looking forward to writing more about how this is implemented in Spin over the coming weeks. Stay tuned!
Fermyon Serverless AI In Action
Let’s take the example of building a simple sentiment analysis bot that takes as input the text to be analyzed and returns one of the following sentiments: positive, neutral, or negative. We will create a small JavaScript endpoint that performs the analysis that we will build and run locally, then deploy to Fermyon Cloud.
Check out the complete example in the Spin Up Hub, and make sure you are following the instructions on how to set up your development environment.
Here is a breakdown of how to build this using Spin:
export async function handler(req, res) {
// Take the request body and prepare the Llama2 prompt.
let input = decoder.decode(req.body);
let prompt = `<s>[INST] <<SYS>>
You are a utility that performs sentiment analysis on the supplied text.
Only respond with one of: positive, neutral, negative.
<</SYS>>
${input} [/INST]
`
// Use the new Llm.infer implementation to perform the inference.
// Control the model, prompt, and inference parameters such as
// number of tokens or temperature.
let inferenceResponse = Llm.infer(InferencingModels.Llama2Chat, prompt, { maxTokens: 20 });
console.log("Executed inference with input " + input + " Result: ")
console.log(inferenceResponse);
// This is a full web application, send the HTTP response.
res.status(200).body(inferenceResponse.text);
}
This is a simple, yet complete application! As with any capability in Spin, we need to declare in the manifest that this component should be allowed to execute the model. Here is the component in spin.toml:
[[component]]
id = "sentiment-analysis"
# this is a WebAssembly component.
source = "component.wasm"
[component.trigger]
route = "/api/..."
# this component is not allowed to make ANY external requests!
allowed_http_hosts = []
# we grant the component the capability to call the Llama2 chat model.
ai_models = ["llama2-chat"]
[component.build]
command = "npm run build"
Now let’s build the application and run it locally:
$ spin build
Finished building sentiment-analysis component.
# run the application locally
$ spin up
Logging component stdio to ".spin/logs/"
Storing default key-value data to ".spin/sqlite_key_value.db"
Serving http://127.0.0.1:3000
Available Routes:
sentiment-analysis: http://127.0.0.1:3000/api (wildcard)
We can start sending requests to our sentiment analysis endpoint locally:
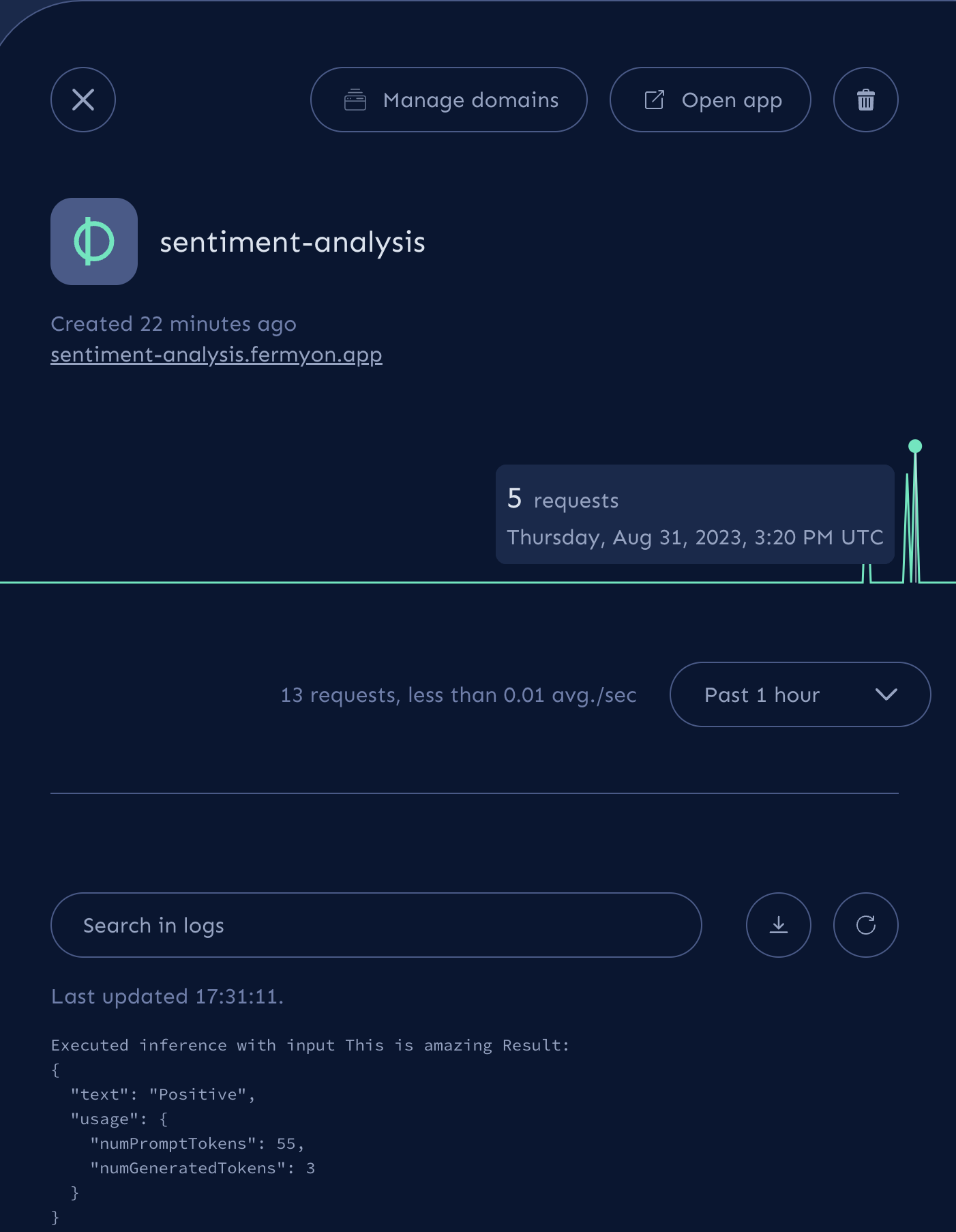
$ curl -X POST -d "This is amazing" http://localhost:3000/api
Positive
Executed inference with input This is amazing Result:
{
"text": "Positive",
"usage": {
"numPromptTokens": 55,
"numGeneratedTokens": 3
}
}
time: 25.328s total
When the request is received, Spin loads the Llama2 language model locally and executes the inferencing operation using the supplied prompt and parameters. We also get access to usage metrics such as the number of input and generated tokens.
It is really slow when running on my Apple M1 laptop. Each request is taking around ~20-30 seconds, since running large language models locally is heavily resource intensive — but we can run entirely offline and perform AI inferencing operations from Spin!
When developing locally, Spin takes advantage of an inference optimization technique called quantization, which lets you execute the inferencing operation on a model with lower precision, which can speed up the inferencing operation, but can also degrade your results. Even so, the operation is extremely slow.
Now that we validated that our application runs correctly, it’s time to deploy it to production and compare the performance. Without rebuilding or changing anything about our application, we can deploy to Fermyon Cloud using spin cloud deploy:
$ spin cloud deploy
Uploading sentiment-analysis version 0.1.0-r62f7e860 to Fermyon Cloud...
Deploying...
Waiting for application to become ready....... ready
Available Routes:
sentiment-analysis: https://sentiment-analysis.fermyon.app/api (wildcard)
A few seconds later and we get the URL for our application, and we can now execute the same request, this time with the application running in Fermyon Cloud:
$ curl -X POST -d "This is amazing" https://sentiment-analysis.fermyon.app/api
Positive
time: 0.758s total
This time, our entire request took around 750 milliseconds! In that time, Fermyon Cloud started my serverless web endpoint and executed an AI inferencing operation on the Llama2 chat model on a high performance GPU!
What Can You Build Using Fermyon Serverless AI Today?
Fermyon Serverless AI gives you the building blocks to add AI to your applications. You can find samples for storing inferencing responses in the Fermyon Cloud key value store, performing semantic searches on embeddings to find relevant context to send to the language model. Putting these capabilities together, a few examples of what you can build include:
- text processing engines (summarization, rewriting text)
- specialized chatbots (documentation bots)
- natural language to code generation using CodeLlama
You can find (and contribute!) samples, tutorials, templates, and examples using the new AI capabilities on the Spin Up Hub. We are excited to learn about your use cases and to understand how to improve the service in the future. If you are interested in this feature, make sure to join our Discord server!
Even though they might appear so at first glance, language models are not magic. They have intrinsic biases and can start hallucinating inputs and predict erroneous outputs. We recommend avoiding scenarios where the language model would generate a large corpus of text unrestrained, and we encourage following the models’ responsible use guide..
Limits, Limitations, and Looking Forward
We are applying some rate limiting and queueing for AI requests to ensure a great experience for our users. You can learn more about the usage limits here. As we understand the usage patterns for AI workloads, we gradually work to raise them.
Currently, we have the following AI models available in Fermyon Cloud:
As we learn about how these models are used, we are really excited to experiment with models of various sizes (both smaller, specialized models as well as 70B parameter models), and allowing users to upload fine-tuned weights (using LoRa weights).
Next Steps: