Local AI Development with Cloud GPUs
 Sohan Maheshwar
Sohan Maheshwar
ai
cloud-gpu
testing
serverless

With the launch of Fermyon Serverless AI, developers can add Large Language Model (LLM) Inferencing to their apps with no extra setup. Running inferencing on LLMs is computationally intensive. When developing and testing your Spin app, you can run inferencing on your local machine. But most development laptops and desktop CPUs are not optimzed to run LLMs that have billions of parameters, so running a single inference query can be painfully slow and CPU-intensive. Another way to test your AI Spin app is to deploy it to the Fermyon Cloud whenever a change is made. This way, we can use a powerful GPU running in the cloud that is optimized to run LLMs, for our inferencing. However, we wouldn’t want to deploy the app to the Fermyon Cloud for every change that is made during the development and testing phase.
What if there was a way to maintain the local development experience of Spin apps, while using a powerful GPU that is running in the cloud? Well, here’s some good news!
This blogpost describes the spin-cloud-gpu plugin that enables local AI development with Cloud GPUs.
Cloud GPU Plugin
The Cloud-GPU plugin essentially serves as a proxy to access GPUs for your local Spin application. While the app is hosted locally (running on localhost), every inferencing request is sent to the LLM that is running in the cloud.
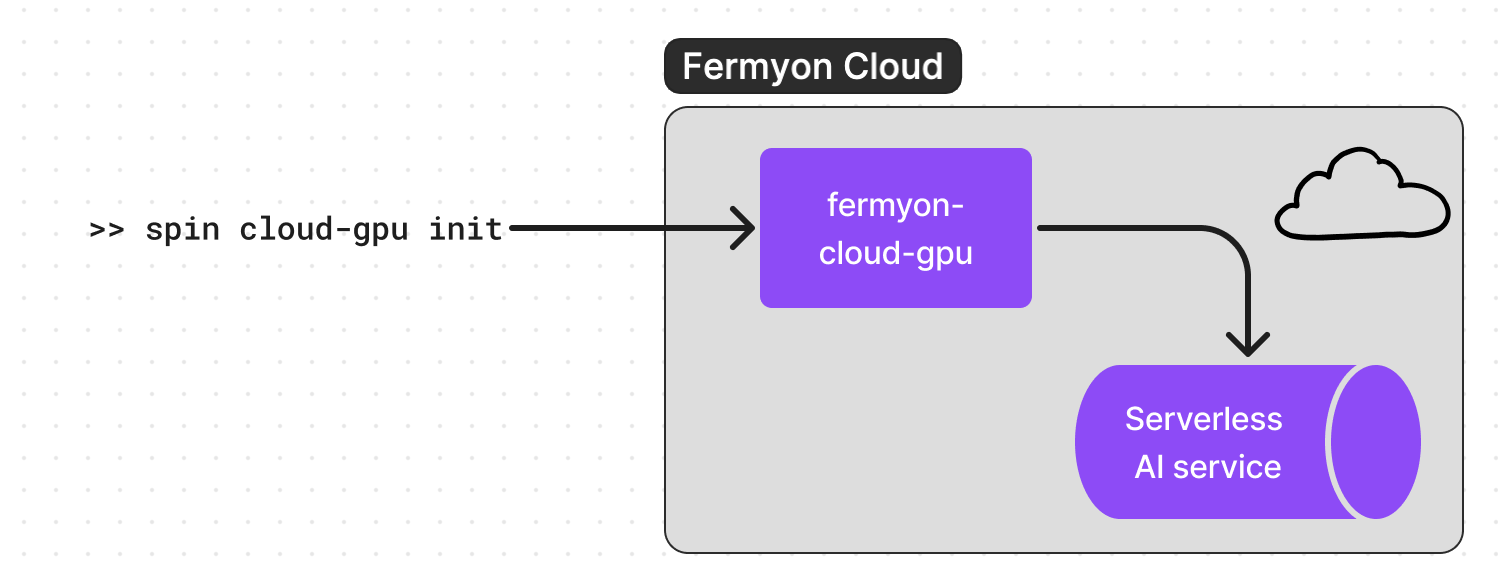
Here’s how you can use the spin-cloud-gpu plugin.
Note: This plugin works only with Spin v1.5.1 and above.
First, install the plugin using the command:
$ spin plugins install -u https://github.com/fermyon/spin-cloud-gpu/releases/download/canary/cloud-gpu.json -y
Let’s initialize the plugin. This command essentially deploys the Spin app to a Cloud GPU proxy and generates a runtime-config. This runtime-config needs to be included in your Spin app to associate with the GPU that is running in the Cloud.
$ spin cloud-gpu init
Deploying fermyon-cloud-gpu Spin app ...
Add the following configuration to your runtime configuration file.
[llm_compute]
type = "remote_http"
url = "https://fermyon-cloud-gpu-<AUTO_GENERATED_STRING>.fermyon.app"
auth_token = "<AUTO_GENERATED_TOKEN>"
Once added, you can spin up with the following argument --runtime-config-file <path/to/runtime/config>.
This is the runtime-configuration. In the root of your Spin app directory, create a file named runtime-config.toml and paste the runtime-config generated in the previous step.
That was it! Now you are ready to test the Serverless AI app locally, using a GPU that is running in the cloud. To deploy the app locally you can use spin up (or spin watch) but with the following flag that indicates the runtime-config:
$ spin up --runtime-config-file <path/to/runtime-config.toml>
Logging component stdio to ".spin/logs/"
Serving http://127.0.0.1:3000
Available Routes:
hello-world: http://127.0.0.1:3000 (wildcard)
Once you are done with testing your app and are ready to deploy it to the Fermyon Cloud, you can destroy the GPU that was created, by using this command:
$ spin cloud-gpu destroy
For more tutorials about Serverless AI application, check out How to Build Your First Serverless AI Application or Building a Sentiment Analysis API using Large Language Models. Happy programming!