How I Built an AI Inferencing API With Llama2 on Spin
 Caleb Schoepp
Caleb Schoepp
Fermyon Serverless AI
LLM
AI
Spin
llama2
Hey my name is Caleb and I’m a software engineer at Fermyon. Just a couple weeks ago we launched the private preview for Fermyon Serverless AI. I wasn’t working directly on this feature but was pretty excited about it so I spent some time last week kicking the tires on this new feature and built a little demo. It was super fun to build and I’ve never had an easier time working with LLMs before. Let me tell you about it.
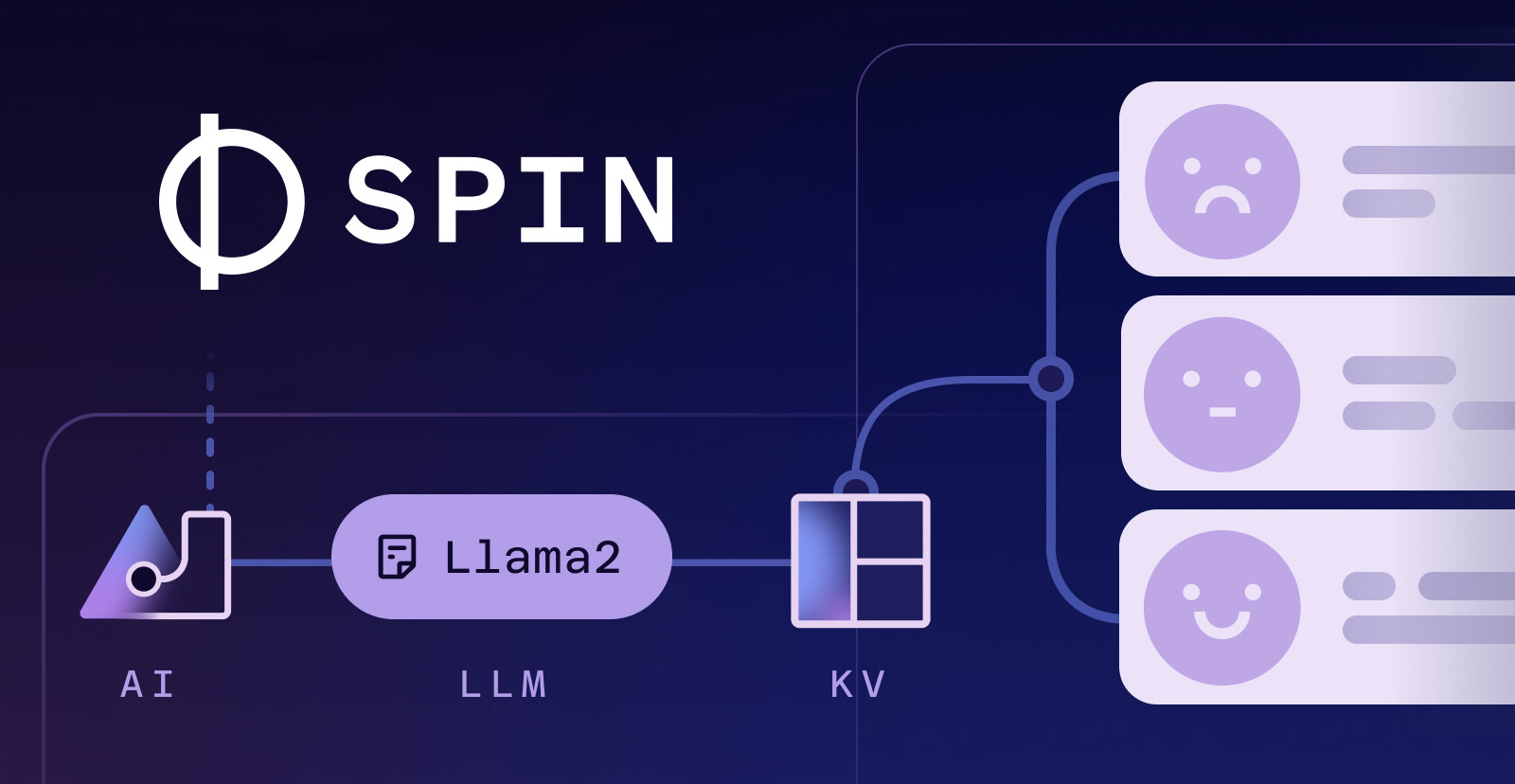
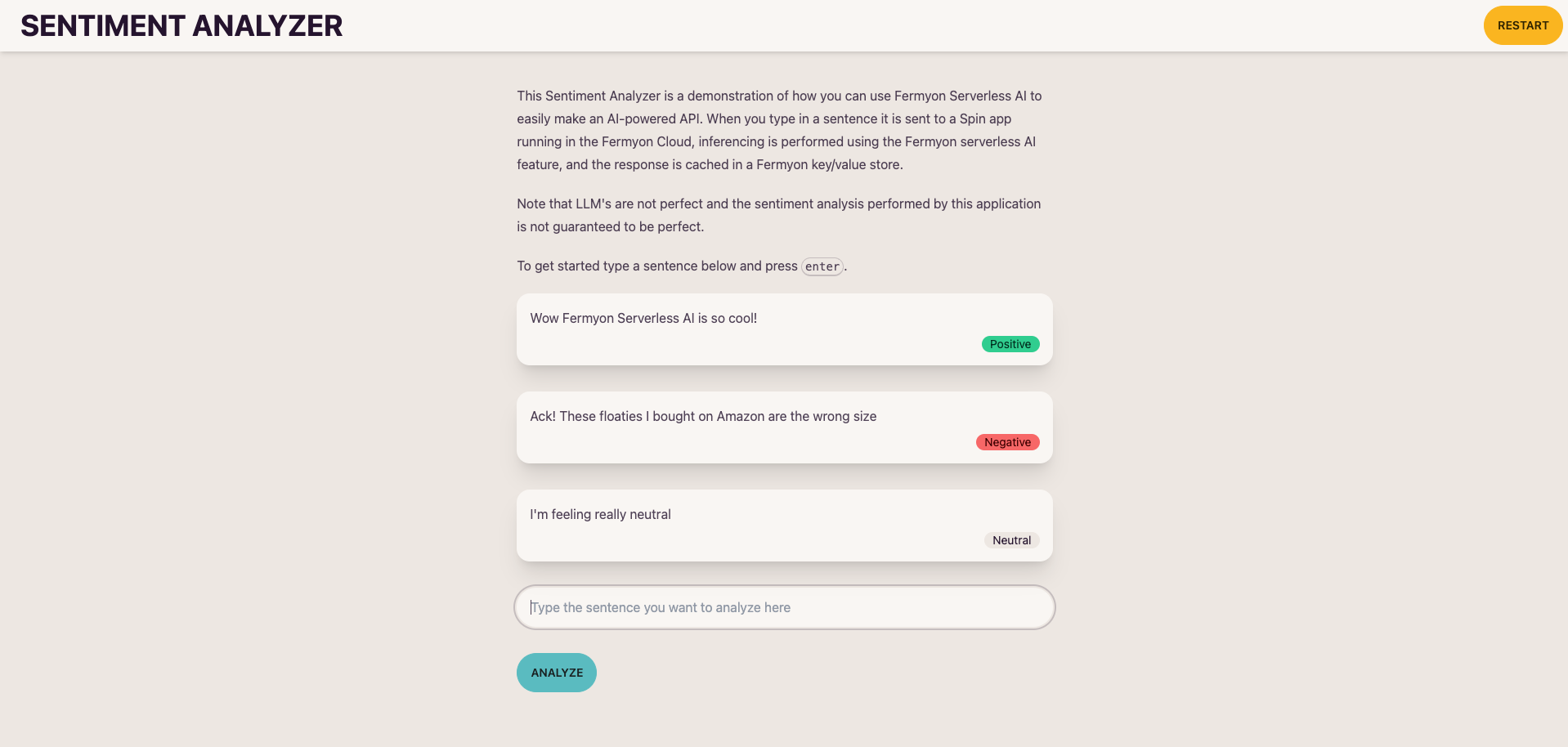
Based on a suggestion from our CTO Radu I decided it would be fun to build a simple sentiment analysis API using the inferencing feature of Fermyon Serverless AI. Sentiment analysis is when you determine if a piece of text has a positive, negative, or neutral sentiment. For example the sentence “I’m having the best day of my life” would be classified as positive. Whereas the sentence “Ack! These floaties I bought on Amazon are the wrong size” would be classified as negative. Sentiment analysis was typically done with more traditional classification models that would have to be trained. But now with a state-of-the-art language model and few-shot learning you can achieve similar results without needing to train a model. Fermyon Serverless AI lets us do this inferencing with the llama2-chat model.
Before we dive into how I actually built the demo let’s look at how you would use the API. After running spin build and spin up on your local machine the API is ready to go and you can query it with cURL.
curl --json '{"sentence": "Ack! These floaties I bought on Amazon are the wrong size"}' http://localhost:3000/api/sentiment-analysis
After making that POST request, the response will look something like the JSON below. If you’re testing this locally, the response is definitely going to take awhile. Running inference on an LLM is very computationally expensive and your laptop is only so amazing. The GPUs we use to do the inferencing in the cloud are much faster. To get around this, responses are cached in a Spin Key/Value store so subsequent requests will be much faster.
{ "sentiment": "negative" }
I also built a simple user interface for the demo to demonstrate the API. Remember you can try it here.
Building the demo
I built the demo using TypeScript and it was easy to scaffold out the Spin application using the spin new command. Inside the spin.toml I configured my Spin component so that it would have access to the llama2-chat AI model and the default KV store. I also configured it so that any HTTP requests matching the pattern /api/... would be routed to my component.
[[component]]
id = "sentiment-analysis"
source = "target/spin-http-js.wasm"
exclude_files = ["**/node_modules"]
key_value_stores = ["default"]
ai_models = ["llama2-chat"]
[component.trigger]
route = "/api/..."
[component.build]
command = "npm run build"
watch = ["src/**/*", "package.json", "package-lock.json"]
Before I started writing code I also downloaded the llama2-chat model and placed it in my .spin/ai-models directory. You can find the model here.
mkdir -p .spin/ai-models
mv ~/Downloads/the-downloaded-model .spin/ai-models/llama2-chat
With that minimal amount of setup done I was ready to write some code. If you want to see all the code at once the source is here. Otherwise let’s go through it piece by piece. First, there is a little bit of code to wire up the API. The Spin router makes it incredibly easy to setup HTTP API routes.
let router = Router();
// Map the route to the handler
router.post("/api/sentiment-analysis", async (_, req) => {
return await performSentimentAnalysis(req);
});
// Entry point to the Spin handler
export const handleRequest: HandleRequest = async function (
request: HttpRequest
): Promise<HttpResponse> {
return await router.handleRequest(request, request);
};
performSentimentAnalysis is where all the magic happens. It starts by parsing the sentence out of the JSON body and then checking to see if we’ve already cached a sentiment for that sentence in the KV store. If there is a match then we just return early with the cached value. This avoids making expensive inference calls to the LLM over and over again.
// Parse sentence out of request
let data = request.json() as SentimentAnalysisRequest;
let sentence = data.sentence.trim();
// Prepare the KV store
let kv = Kv.openDefault();
// If the sentiment of the sentence is already in the KV store, return it
let cachedSentiment = kv.get(sentence);
if (cachedSentiment !== null) {
return {
status: 200,
body: JSON.stringify({
sentiment: decoder.decode(cachedSentiment),
} as SentimentAnalysisResponse),
};
}
If we don’t find a hit in the cache then we’ll need to run the inference on the LLM. This is as easy as calling Llm.infer. It’s pretty impressive that we’re able to harness the power of a 13 billion parameter LLM with just a single line of code — more on this later. We also take the liberty to set a few special inferencing parameters. I figured that a lower temperature and a small max_tokens count would be conducive to performing sentiment analysis where we only want a single word response of positive, negative, or neutral.
const PROMPT = `\
<<SYS>>
You are a bot that generates sentiment analysis responses. Respond with a single positive, negative, or neutral.
<</SYS>>
[INST]
Follow the pattern of the following examples:
User: Hi, my name is Bob
Bot: neutral
User: I am so happy today
Bot: positive
User: I am so sad today
Bot: negative
[/INST]
User: {SENTENCE}
`;
// Otherwise, perform sentiment analysis
let options: InferencingOptions = { max_tokens: 6 };
let inferenceResult = Llm.infer(
InferencingModels.Llama2Chat,
PROMPT.replace("{SENTENCE}", sentence),
options
);
I think it’s important to take a moment to quickly acknowledge that sentiment analysis can be a tricky problem to solve and that the prompt we’re using is very naive. The purpose of this demo is to show off the power of using LLMs together with Spin, not to build a production ready sentiment analysis API.
Anytime you’re working with a LLM you’ll have to do a bit of post processing on the results. In our case we split the result into a list of words in case the LLM generated a multi-word response. Then we just take the first word of that list. Next we default to unsure if the sentiment the model produced is invalid.
let sentiment = inferenceResult.text.split(/\s+/)[1]?.trim();
// Clean up result from inference
if (
sentiment === undefined ||
!["negative", "neutral", "positive"].includes(sentiment)
) {
sentiment = "unsure";
}
Finally we return the result to the user. If we’re sure about the result we also make sure to cache it in the KV store.
// Cache the result in the KV store
if (sentiment !== "unsure") {
console.log("Caching sentiment in KV store");
kv.set(sentence, sentiment);
}
return {
status: 200,
body: JSON.stringify({
sentiment,
} as SentimentAnalysisResponse),
};
That’s all it takes to build a simple sentiment analysis API using Fermyon Serverless AI.
A match made in heaven
If you’ll allow me I’d like to spend a bit of time gushing about how excited I am that we’re launching Fermyon Serverless AI. In the past year I’ve worked on multiple applications that leveraged the powers of LLM chat models and each time there was lots of challenges. Two things stand out to me about Fermyon Serverless AI that make it meaningfully better: the ease of using an open source LLM and the surrounding NoOps data services.
In all the AI enabled applications I’ve built before today I’ve used the OpenAI API. GPT-3 and GPT-4 are phenomenal models but they don’t work for everyone. Personally the biggest issue I’ve run into with them is that it is simply too expensive to have any sort of automated testing that uses them. This makes it very difficult to iterate because you aren’t using the real model in your CI/CD. Using an open source model like LLama2 that you can run yourself solves this issue but has been impractical to do until now. Fermyon Serverless AI makes using an open source model like this as easy as a single line of code with no operations work — pretty amazing.
The second thing that is great about Fermyon Serverless AI is that it is surrounded by the rest of the NoOps data services offered in the Fermyon Cloud. I’m talking about Key/Value stores and SQL databases all available with a single line of configuration. In my demo I used the KV store to cache the results of the sentiment analysis. But, you can also use a SQL database to store embeddings that you’ve generated. Along with the serverless paradigm of a Spin app I think that writing an AI enabled application or API has never been easier.
Closing
Hopefully you’re as excited about the new Fermyon Serverless AI as I am. Whether you want to learn more about it or just want to dive straight in here are some links to get you started: