Turbocharging Broken Link Checking
 Tim McCallum
Tim McCallum
spin
cron
trigger
rust
CI
CD

Link checkers are super important and useful. But many potential improvements could make them even better. For example, they could:
- check links in parallel, using distributed computing, instead of checking links one at a time.
- check links from distributed locations, instead of from a single server.
- check links in a random order, instead of the order in which they appear in your content.
- cache results for instant information, instead of starting to check only when building a website.
- check links 24/7/365, instead of only when updating content.
In this blog, I introduce a novel (and very experimental) link-checking tool that leverages the power of distributed computing. This experimental tool utilizes Wasm-powered applications running on distributed nodes, which operate continuously through a Cron trigger mechanism. These nodes synchronize data with a centralized Cloud API, ensuring efficient and reliable link checking around the clock.
One of my goals while building this tool is to use as many features of Spin and Fermyon Cloud as possible. For example, when you read on, you will discover that I have used Spin variables from applications, Spin Key-Value Store, Spin Cron Trigger (experimental support for creating and running components on a schedule), and SQLite storage. I also went ahead and applied a custom Fermyon subdomain, used the static file server for Spin applications to whip up a frontend which queries the application’s data, and enabled CORS along the way, using some helpers for building HTTP-APIs with Fermyon Spin.
You can see it running live on Fermyon Cloud.
Background
We at Fermyon check every link within our content as part of our continuous integration and continuous delivery (CI/CD) pipeline. Most companies and projects do something very similar (using pre-existing libraries) to ensure their websites or applications maintain link integrity at the time of site deployment. Whenever I trigger a link checker to run, I am reminded of the bottlenecks and pitfalls. The main takeaway, each time, is that link checkers are very slow. Let’s discuss some of the pitfalls of traditional link-checking mechanisms.
Quantity and Timing
Link checkers check all of the links at once (during a build, as part of the CI/CD pipeline), which means that the website’s build process is held up for a considerable amount of time (up to 10 to 15 minutes, perhaps much longer). For example, our developer documentation has over 16, 500 links and counting. Sitting on the edge of your seat waiting is not ideal. Neither is only learning about a broken link at the time of build, which in some cases has nothing to do with your content changes (the link has normally just stopped working on a third-party site for some reason).
The timing of link checking is important. Links should be checked at all hours of the day and night, not just at build time. And come build time, the link-checking part should be instantaneous. We don’t want to wait if we don’t have to!
False Positives
Sometimes, there is a discrepancy between what a link checker tells you and what you experience when manually testing that link in your browser. More often than not, the solution for this “false positive” is to add this suspect URL to a list of false positives (where it will be ignored by the link checker in the future). The issue with this false positive solution is that if that third-party URL does break (at some point in the future) the link checker in the CI/CD will never know. We don’t want to leave a broken link in our content for a user to discover.
Overwhelming Endpoints
If a website heavily links to pages on a specific third-party website, then the “all-at-once” CI/CD approach may overwhelm that third-party website. This is not ideal and may result in the third-party website giving back untrue failures (return 500, 503, or 429 HTTP response status codes) as part of its own rate-limiting functionality. You can’t control how the third-party website handles your broken link check requests, but you can change how links are checked. We don’t want to check links to the same host repeatedly. We want to allow distributed nodes to check them in a random order at all hours of the day and night.
Below I introduce a personal, and very experimental pet project, called Link Test Live.
Link Test Live (An Experiment)
Link Test Live (let’s call it LTL for short) is a light-bulb idea that came to me while writing trigger documentation, specifically introducing the Spin Cron Trigger.
“What if, instead of HTTP triggers - humans clicking buttons or committing/pushing changes in their Command Line Interface (CLI) - we could automate broken link checking as a repeatable time-based task?”
“Better still, what if we could do this using distributed computing to share the load?”
LTL is a self-managing distributed ecosystem of link checkers and a central API. Each link checker (node) is a Spin application that you can quickly run on your local machine. Your node (participation in the distributed part) gets an API key from the central LTL Cloud API. You can add links that you would like checked by the nodes on the network. You can call the LTL Cloud API to get the status of the links that you are interested in. All via secure HTTP requests. That’s about it. (The self-managing part means neither you nor I have to be involved once the pieces are wired up). We can get on with living.
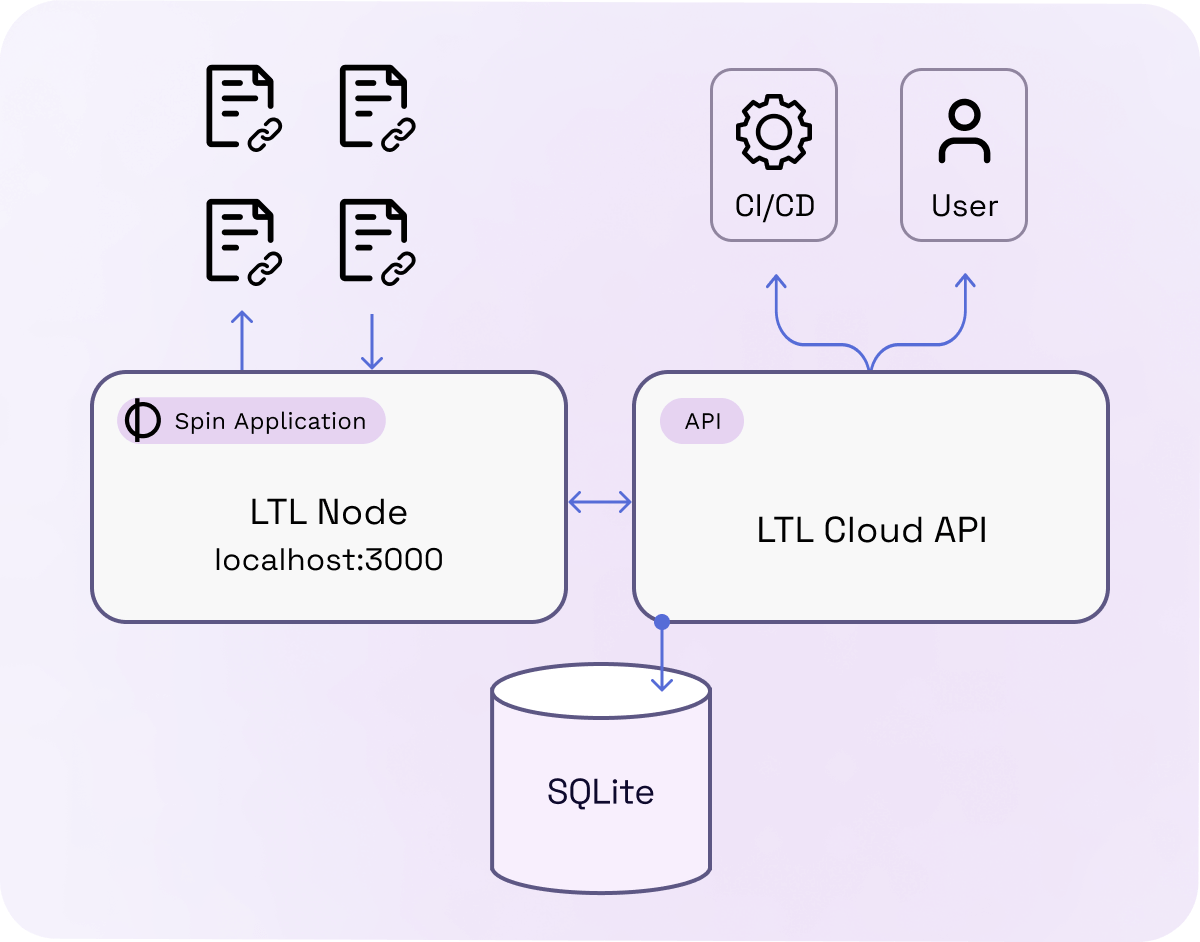
The diagram above illustrates how a user or automated CI/CD can interact with the LTL Cloud API via secure HTTP requests. All of the information is managed inside the SQLite database in Fermyon Cloud. The node software runs on its own, thanks to the Spin Cron Trigger.
Let’s discuss some of the upsides and then dive into the actual software service.
Entropy
The distributed computing approach of LTL uses entropy for two main reasons:
- To reduce load: The LTL Cloud API uses entropy when selecting which links are given out to nodes that want to perform link checking. Third-party sites receive fewer consecutive requests (avoiding rate-limiting issues) and the huge list of links to check is shared randomly amongst the participating nodes (getting the job done faster).
- To perform quality control, the results coming back from each node can be randomly sampled to conduct swift quality control and award points to that node for participating.
Distributed Computing
Checking links
Sharing the load between nodes carries the advantage of speed and volume. Each node only needs to check a small number of links each hour to create a very large database of checked links. For example, the default configuration for each node is to check 5 links per minute. That’s 300 links per hour. With 100 nodes working together, that’s 30, 000 fresh link checks per hour.
Obtaining results
The results from any of the pre-checked links can be accessed instantly via the LTL Cloud API. Providing more volume than a linear CI/CD link checker can provide in the same time frame. In a hypothetical example, checking 20, 000 links might take 15 minutes (using a traditional broken link checker approach). If the LTL Cloud API can return results for those 15, 000 links within a 1 minute window, that is a time-saving of 93.33%!
Better Control of Your Content
As mentioned above, you can’t control third-party sites. Pages on those sites can go down at any time. Without LTL, you will not know about broken links until you build your content next. The LTL Cloud API constantly gets refreshed information from the distributed nodes, facilitating around-the-clock broken link checks via the LTL Cloud API. Check links whenever you want, not just at build time.
Your Journey Begins
Let’s get you a node all set up so you can start.
Installing Spin
If you haven’t already, please go ahead and install the latest version of Spin.
Upgrading Spin: If you have an older version of Spin, please see the Spin upgrade page.
Download LTL
Checkout the repository and change into the application directory:
# Checkout the repository
git clone https://github.com/tpmccallum/link-test-live.git
# Change into the application directory
cd link-test-live/link-test-live-cron
Start Your Node
Use the following command to run your LTL node:
## From the link-test-live/link-test-live-cron directory
spin build --up
On its maiden voyage, your node will fetch an API key from the Cloud API and automatically save it inside your node’s key-value storage.
Links Per Batch Configuration (Optional)
Your node is pre-configured to check links in batches of 5. You can update this by changing the default value in the spin.tom file:
[variables]
links_per_batch = { default = "5" }
You can also create a system variable in the terminal session where your node is running:
export SPIN_VARIABLE_LINKS_LINKS_PER_BATCH="5"
Cadence Configuration (Optional)
The trigger.cron section can be updated to increase or decrease the cadence. The cron_expression has the following fields:
# ┌──────────── sec (0–59)
# | ┌───────────── min (0–59)
# | │ ┌───────────── hour (0–23)
# | │ │ ┌───────────── day of month (1–31)
# | │ │ │ ┌───────────── month (1–12)
# | │ │ │ │ ┌───────────── day of week (0–6)
# | │ │ │ │ | ┌─────────────- year
# | │ │ │ │ | │
# | │ │ │ │ | │
0 * * * * * *
The default setting is to run a new link-checking batch of 5 URLs every 1 minute:
[[trigger.cron]]
component = "link-test-live-cron"
cron_expression = "0 * * * * * *"
Your node will just tick away while you get on with your day (no need to beef up the settings or play with it). Your output will look like the following:
Checking for API key, please wait ...
Fetching new batch of links to check ...
Using API Key Some("bef8596e-DC0A-4356-B4E9-74CD2B4A329E")
Processing: https://developer.fermyon.com/spin/v2/kubernetes
Processing: https://developer.fermyon.com/spin/v2/quickstart
Processing: https://developer.fermyon.com/spin/v2/http-outbound
Processing: https://developer.fermyon.com/cloud/quickstart
Processing: https://developer.fermyon.com/spin/v2/testing-apps
Reset
If you do want to stop your node from running you can hit Ctrl + C. This may leave the internal busy=yes/no value a bit confused. So, next time you start your node (using spin up) if you see a message like the one below, please just do as it asks and visit the localhost:3000/reset link to reset the internal busy value:
Checking for API key, please wait ...
Still busy checking the last batch of links. Will try again later ...
If you used Ctrl + C to stop you can visit this link
< http://localhost:3000/reset >
to reset the busy flag!
The just sit back and relax, it will continue when the cron schedule is due.
The busy value just makes sure that your node does not ask for more links to check before it has finished the last batch.
Obtaining Results
The LTL Cloud API can be reached using the following secure HTTP request:
curl -X POST https://link-test-live-cloud.fermyon.app \
-H "Content-Type: application/json" \
-d '{
"api_key": "bef8596e-DC0A-4356-B4E9-74CD2B4A329E",
"links_to_check": [
"https://developer.fermyon.com/spin/v2/testing-apps",
"https://developer.fermyon.com/spin/v2/kubernetes",
"https://developer.fermyon.com/spin/v2/http-outbound"
]
}'
If the URLs are not in the system, an empty result set will be returned i.e. {"results":[]}.
Of course, you are free to make this call in the language of your choice. Appendix A has some Python and Javascript examples.
The good news is, if you don’t see your URLs in the system you can add them via the API:
curl -X POST https://link-test-live-cloud.fermyon.app \
-H "Content-Type: application/json" \
-d '{
"new_additions": [
"https://developer.fermyon.com/spin/v2/testing-apps",
"https://developer.fermyon.com/spin/v2/kubernetes",
"https://developer.fermyon.com/spin/v2/http-outbound"
]
}'
At which point you may see that the status of the URLs are still To Be Determined (TBD):
{
"results": [
{
"single_url": "https://developer.fermyon.com/spin/v2/http-outbound",
"status": "TBD"
},
{
"single_url": "https://developer.fermyon.com/spin/v2/kubernetes",
"status": "TBD"
},
{
"single_url": "https://developer.fermyon.com/spin/v2/testing-apps",
"status": "TBD"
}
]
}
After a little time has passed you will notice that the URLs have been updated by one of the nodes on the system:
curl -X POST https://link-test-live-cloud.fermyon.app \
-H "Content-Type: application/json" \
-d '{
"api_key": "bef8596e-DC0A-4356-B4E9-74CD2B4A329E",
"links_to_check": [
"https://developer.fermyon.com/spin/v2/testing-apps",
"https://developer.fermyon.com/spin/v2/kubernetes",
"https://developer.fermyon.com/spin/v2/http-outbound"
]
}'
As shown below, the URLs have been checked and are showing a healthy 200:
{
"results": [
{
"single_url": "https://developer.fermyon.com/spin/v2/http-outbound",
"status": "200"
},
{
"single_url": "https://developer.fermyon.com/spin/v2/kubernetes",
"status": "200"
},
{
"single_url": "https://developer.fermyon.com/spin/v2/testing-apps",
"status": "200"
}
]
}
A great way to automate getting links into the system would be to parse a website’s sitemap and then make a secure HTTP request for each URL in each of the website’s pages. Here is an example written in Python:
import time
import json
import requests
import xml.dom.minidom as minidom
from bs4 import BeautifulSoup
## website_sitemap variable
website_sitemap = requests.get('https://developer.fermyon.com/sitemap.xml', allow_redirects=True).text
parsed_website_sitemap_document = minidom.parseString(website_sitemap)
website_sitemap_loc_elements = parsed_website_sitemap_document.getElementsByTagName('loc')
website_page_urls = []
for website_sitemap_loc_element in website_sitemap_loc_elements:
website_page_urls.append(website_sitemap_loc_element.toxml().removesuffix("</loc>").removeprefix("<loc>"))
print("Number of page to process is {}\n First page to process is {} and the last page to process is {}".format(len(website_page_urls), website_page_urls[0], website_page_urls[len(website_page_urls) - 1]))
page_url_dict = {}
page_int = 1
for one_page in website_page_urls:
print(f"Processing {one_page}")
page_url_dict = {}
temp_list = []
response = requests.get(one_page)
if response.status_code == 200:
if one_page.startswith("http"):
soup = BeautifulSoup(response.content, 'html.parser')
links = soup.find_all('a')
urls = [link.get('href') for link in links]
urls = [url for url in urls if url is not None and (url.startswith('http') or url.startswith('https'))]
urls = list(set(urls))
url = "https://link-test-live-cloud.fermyon.app"
headers = {"Content-Type": "application/json"}
data = {
"new_additions": urls
}
response = requests.post(url, headers=headers, json=data)
The LTL Cloud side of things will take these links and organize them in such a way that the unchecked and older links get provided to nodes as a priority. As mentioned above (whilst sorted by freshness and age) the links dished out to the nodes for checking are randomized also. The Cloud API is driven by SQLite Database support in Fermyon Cloud.
Conclusion
In closing, I just want to reiterate this link-checking tool is an experiment. It has provided a great opportunity to use as many of the features that Spin and Fermyon Cloud offer. I hope this experiment can translate into water-cooler currency for you, and you can discuss and share this with your colleagues. Feel free to download the software, start your node, and earn points. You might also have some good ideas about extending this initial idea.
Future Features
At present, the only way to communicate with the LTL Cloud API is via secure HTTP requests, but this could be updated in the future.
Future features could include:
- A notification system that can email/text when a link goes down.
- A dashboard that allows node owners to fill out their profiles. Adding location/continent and other details will help improve the granularity of the information (links may only work in some parts of the world due to larger network outages, etc.).
- A dashboard that shows your links (the ones harvested from your website) as green (working) and red (broken)
- Instead of using only one polling modality with Cron, perhaps we could use the Message Queuing Telemetry Transport (MQTT) trigger for Spin and have both Cron and MQTT options.
- A dashboard mechanism (perhaps a web form) that can take a single URL and then execute a script like this one, which traverses the entire website (finds all of the outbound links and writes the SQLite syntax to load these URLs into the Cloud API).
- An option to restrict which URLs a node can check. Link checkers will naturally want to be able to check any link. But Spin applications offer a level of security that lets you (the node operator) allow only certain hosts to be visited from your app. Here is a brief word on the matter:
Outbound Hosts Configuration (Future Feature Request)
Your node is preset to allow outbound connections to all hosts, using the following wildcard:
[variables]
# --snip--
host_whitelist = { default = ["https://*"] }
# --snip--
[component.link-test-live-cron]
# --snip--
allowed_outbound_hosts = ["https://*"]
# --snip--
Wasm’s sand-boxed execution means no technical or security side-effects will occur if you check links from unknown hosts. Changing this configuration is just a personal preference. Just keep in mind that broken link checkers are not restricted in this way.
However, if you do, indeed, want to restrict which outbound hosts to check, then will need to update the spin.toml file. For example:
- Replace the
allowed_outbound_hosts value as shown below. But remember, if you are going to use this optional configuration, the https://link-test-live-cloud.fermyon.app is mandatory ( because that is how your node talks to the LTL Cloud API).
- Replace the default
host_whitelist value in the [variables] section or set an environment variable i.e. export SPIN_VARIABLE_HOST_WHITELIST='["[https://developer.fermyon.com](https://developer.fermyon.com/)"]'
Application manifest example with restricted outbound hosts:
[variables]
# --snip--
host_whitelist = { default = ["https://developer.fermyon.com"] }
# --snip--
[component.link-test-live-cron]
# --snip--
allowed_outbound_hosts = ["https://link-test-live-cloud.fermyon.app", "https://developer.fermyon.com"]
# --snip--
Any Questions
If you have future feature suggestions, please create an issue in the repository.
Appendix A
Python:
import requests
url = "https://link-test-live-cloud.fermyon.app"
headers = {"Content-Type": "application/json"}
data = {
"api_key": "bef8596e-DC0A-4356-B4E9-74CD2B4A329E",
"links_to_check": [
"https://developer.fermyon.com/spin/v2/testing-apps",
"https://developer.fermyon.com/spin/v2/kubernetes",
"https://developer.fermyon.com/spin/v2/http-outbound",
],
}
response = requests.post(url, headers=headers, json=data)
JavaScript:
const url = "https://link-test-live-cloud.fermyon.app";
const headers = {
"Content-Type": "application/json"
};
const data = {
"api_key": "bef8596e-DC0A-4356-B4E9-74CD2B4A329E",
"links_to_check": [
"https://developer.fermyon.com/spin/v2/testing-apps",
"https://developer.fermyon.com/spin/v2/kubernetes",
"https://developer.fermyon.com/spin/v2/http-outbound"
]
};
fetch(url, {
method: 'POST',
headers: headers,
body: JSON.stringify(data)
})
.then(response => response.json())
.then(data => {
console.log('Success:', data);
})
.catch(error => {
console.error('Error:', error);
});