Building Comprehensive Compute Platforms
 Mikkel Mørk Hegnhøj
Mikkel Mørk Hegnhøj
platform
component
wasm
wasi-http
wasmtime

With the release of Spin 2.0, Spin now supports WebAssembly (Wasm) components natively. In a recent blog post, Kate Goldenring wrote about how composing applications using components is now possible, go check out that post as a good addendum to what you’re about to read here.
As a TL;DR, what Kate focused on describing is the scenario, where you want to add functionality to your components, by composing in other components. Specifically, Kate wanted to outsource the responsibility of authorizing the caller to the business logic she implemented, to a separate component.
Delegating Responsibilities
In many ways, what the Wasm Component Model (component model from now on) enables, is to delegate responsibilities to implementations made by others. This is in no way foreign to what we do on a daily basis, by importing libraries in our source code, building container images based on layers provided by others, hosting our applications on operating systems we didn’t build, and so on and so forth. Matt recently covered how the component model impacts the scenario of using libraries at development time.
In this blog post, I’ll dive deeper into what the component model can do for platform builders and platform engineers to take on more responsibility, by showing how the interfaces provided by platforms to developers, can be at much higher abstractions than what we are used to today.
The Demand for Ad-Hoc Compute Resources
Let’s start with a bit of a history detour to set the context.
As the demand for ad-hoc or on-demand compute resources emerged, companies started providing comprehensive utility computing platforms with automated service management and abundant computational resources. They could be fulfilled by packing a lot of hardware into “a few” data centers around the world and selling those resources (processors, memory, and storage) to multiple customers with a pay-for-what-you-use business model. A great article talking more about the evolution of cloud computing was published by CRV recently.
In order to be able to deliver the technical solutions, the new cloud vendors started developing interfaces to those comprehensive utility computing platforms. Typically, Virtual Machines (VMs), or proprietary Platform as a service (PaaS) interfaces, were offered to customers. Later, with the rise of Docker and containers, an abundance of container orchestration platforms were introduced as that interface, which today is almost ubiquitously Kubernetes. As the saying goes, no one will probably get fired if they choose to build and offer a Kubernetes platform to developers. That’s a good sign of broad industry adoption.
Today’s Options for Building Platforms
In many enterprises, proprietary platforms have been built over the years, which have a very high degree of abstracting away concerns like authentication and authorization to backend systems (think mainframes and the like) and provide easy building blocks to quickly churn out new user interfaces, and applications, fully integrated with those backend systems. However, many of these systems are very expensive to upgrade and move to newer technologies, and they may not easily be able to provide the technology choices that developers want to work with today.
Fortunately, with the rise of Kubernetes and the formation of the Cloud Native Computing Foundation (CNCF), more and more open-source projects have gained traction in helping standardizing what developers can expect from platforms to run their applications. Backstage is a good example of how platform teams can pave the way for developers to choose a technology stack that fits their needs. However, what teams provide on those paved paths are typically standardized installations of well-known Open Source Software (OSS) platforms - e.g., databases like Postgres, a RabbitMQ instance, a Kubernetes Namespace, Graphana for dashboards, etc.
In many ways, what you’re left with as options today are:
- A: A very low-level Application Programming Interface (API)
- A virtual machine or container runtime (basically operating systems)
- B: Proprietary platforms
We know there’s a lot of code to write (I’ve previously read suggestions that we’ll need to accelerate application delivery by a factor of twelve). AI will probably play a huge role in this, but to Matt’s point in his blog, many hours are spent re-implementing solutions to solved problems. Being productive in delivering those applications is crucial for anyone in the software industry.
So can we do better?
Rethinking What You Can Offer Developers
What if the platforms we can build could describe high-level subject-matter concerns? What if we don’t deploy containers or functions but deploy data processing logic, combine some PCI compliance in there, and a data privacy firewall? What would a platform that does that look like, and could we do this today?
In the component model, there is a concept of guests and hosts, which are used to describe the relationship between two components. The host in that relationship has exported interfaces defined, which the guest can call. Hosts can also play the role of a guest in a relationship with other components, which gives you the ability to chain many components together, basically describing a call graph of components.
Let’s add a concrete example to the above explanation. The below code can be found in this repo.
We need to implement an API that enables changing a customer record in our system. Something that seems a somewhat tedious task. Now, if we have a good CRM system (most do), it probably already provides RESTful endpoints to integrate with the data owned by the system. This is a good case of having left the responsibility of authorization, consistency, etc., to that data to the CRM system. But for this example, let’s say we must build the API directly on top of a database. It is not uncommon to use our preferred API framework in our preferred language, implement the required HTTP methods, compile it and deploy it in a container image. However, all the responsibility of what that code can do with the data is handed over to that implementation, and there may be a lot of concerns to deal with, which are not necessarily tied to the actual logic implemented. E.g., data validation, obfuscation of Personally Identifiable Information (PII), etc. It’s not unreasonable to think of a scenario where we don’t want to reveal a social security number to the code but still want it to be able to change it.
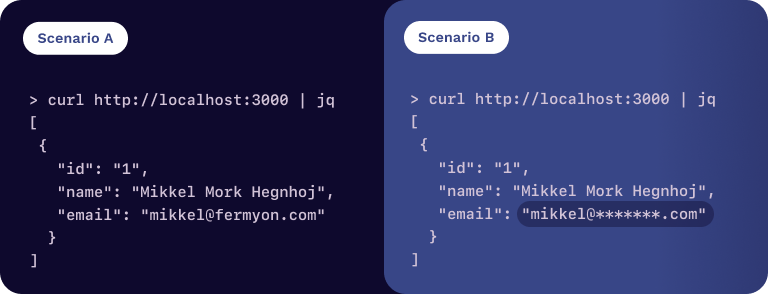
In this example, we want to obfuscate e-mail addresses, or at least the domain as part of an e-mail address. In scenario A below, we would build one component which directly accesses the database, so no data is being obfuscated. Now, we could write the code to obfuscate the data in that component, but we can actually do this in a way where the non-obfuscated e-mail addresses never become available to that component.
In scenario A, the code in “My Code” imports the sqlite interface. This is fulfilled by the host runtime, which sets up the database connection on a socket and calls the database:
// Creates a connection to a database named "default"
let connection: Connection = sqlite::Connection::open("default")?;
// Executes a query
let result: QueryResult = connection.execute("SELECT * FROM customers;", &[])?;
// Serializes the QueryResult into the Customer struct
let customers: Vec<Customer> = result
.rows()
.map(|row| Customer {
id: row.get::<u64>("id").unwrap().to_string(),
name: row.get::<&str>("name").unwrap().to_owned().to_string(),
email: row.get::<&str>("email").unwrap().to_owned().to_string(),
})
.collect();
In scenario B, we inject a sqlite-proxy to take care of the concern about obfuscating the data. The sqlite-proxy component exports and imports the sqlite interface, thus acting as a “middleware” for communicating with the database in-between “My Code” and the host runtime, which ultimately calls the database.
Let’s look at the code. The first thing to notice is that the code in “My Code” is unchanged. This is because the interface it requires (imports) is the same interface we implement (and export) in the sqlite-proxy. The sqlite-proxy also imports the same interface, which the host runtime exports:
// Creates a connection to a database named "default"
let connection: Connection = sqlite::Connection::open("default")?;
// Executes a query
let result: QueryResult = connection.execute("SELECT * FROM customers;", &[])?;
// Serializes the QueryResult into the Customer struct
let customers: Vec<Customer> = result
.rows()
.map(|row| Customer {
id: row.get::<u64>("id").unwrap().to_string(),
name: row.get::<&str>("name").unwrap().to_owned().to_string(),
email: row.get::<&str>("email").unwrap().to_owned().to_string(),
})
.collect();
---
// In the sqlite-proxy, we can now rewrite the execute function
// to manipulate the QueryResult returned from the database
fn execute(&self, statement: String, parameters: Vec<Value>) -> Result<QueryResult, Error> {
let parameters = parameters.into_iter().map(Into::into).collect::<Vec<_>>();
// Get the QueryResult from the query
let mut query_result: QueryResult =
self.0.execute(&statement, ¶meters).map(From::from)?;
// We can now pass the QueryResult through our e-mail detection and domain-name obfuscation function: is_email and hide_email_domain. Both removed here to keep the example shorter.
for row_result in query_result.rows.iter_mut() {
for value in row_result.values.iter_mut() {
match value {
Value::Text(v) => {
if is_email(v) {
*v = hide_email_domain(v);
}
}
_ => {}
}
}
}
// And return the QueryResult, with the manipulated data
Ok(query_result)
}
Running the example yields the following results.
Why Is This Different?
Could we do all of the above with today’s technology? Probably, but Wasm components offer a more elegant way:
- Each components can be written in any language which supports Wasm and the component model (no lock-in to the programming language).
- No dependency at compile time.
- The PII component can be linked at runtime (no need for the owner of My Code) to even know it exists in the platform. This can be done by personnel dedicated to compliance.
- No dependency at deployment time.
- The PII component can, because of the strict isolation of memory between webassembly components, be deployed independently of My Code, and instantiated only at runtime.
- No need to have an always-running process to handle this concern.
All of the above goes back to the comprehensiveness of the utility computing platform needed today. Comprehensiveness is not a matter of which frameworks, databases, or network protocols the platform supports. It can be a matter of anything, that is specific to a business, an industry, an architecture, etc.
A Real-World Use-Case With Wasi-HTTP, Three Companies and an Alliance
Today, the first example of how multiple platform builders have come together to increase the comprehensiveness of platforms while removing vendor lock-ins is available to you.
As part of the Wasm standard, WASI HTTP is a proposed Wasm System Interface API.
The WASI-http proposal defines a collection of interfaces for sending and receiving HTTP requests and responses. WASI-http additionally defines a world, wasi:http/proxy, that circumscribes a minimal execution environment for wasm HTTP proxies.
Today, at least four different implementations of hosts supporting that interface exists: Fermyon Spin, NGINX Unit, WasmCloud, and Wasmtime.
This means I can build a function that handles HTTP requests using any Wasm-supported programming language and have any platforms/hosts run it.
Check out this GitHub repository, which uses Fermyon Spin to create a WASI-http compliant Wasm component, and run it using Spin, Fermyon Cloud, F5 Nginx Unit, and Wasmtime. Also, check out the containerd-wasm-shims project, to enable Spin and Wasmtime in Kubernetes.
Where Are We and What’s Left to Do?
Although we can show examples of how components can help us build more comprehensive platforms, a lot of technical “stuff” is still left for this to be a broadly adoptable vision:
- How do we share and distribute components, opening up for possibilities of creating marketplaces and creating economics for component building?
- How do we orchestrate component graph executions in an environment? (Fermyon Cloud is already doing this, but we need broader support)?
- … and more
Fermyon was founded with a mission to pioneer the next wave of cloud-computing. We hope this article leaves you with the impression that that is what is happening. That it has inspired you to join us on this journey, to solve fundamental problems and help us enable a much more efficient way of using our compute, and much more important, the human resources and the time we have available.Fermyon was founded with a mission to pioneer the next wave of cloud computing. We hope this article leaves you with the impression that that is what is happening. That it has inspired you to join us on this journey, to solve fundamental problems and help us enable a much more efficient way of using our compute, and, much more importantly, the human resources and the time we have available.