Thwarting AI Bots with Edge Content Rewriting
 Matt Butcher
Matt Butcher
wasm
webassembly
bots
spin
ai
I was stunned to learn recently that at any given moment, there are now more bots than humans on the web. Of course, we know of the crawlers and spiders that maintain search indexes. And we’ve heard plenty about the nefarious botnets that cause havoc in the form of DDoS attacks. Most recently, AI bots are consuming content either to generate and tune LLMs or as part of agentic behaviors.
All of these bots are causing problems. At Fermyon we’ve started taking a good solid look at how to solve these problems.
A Sampling of The Bot Problems
Here are a few of the problems that we’re hearing about. All of these are caused by bots, but the sources and impacts are distinct.
Competitive Scrapers
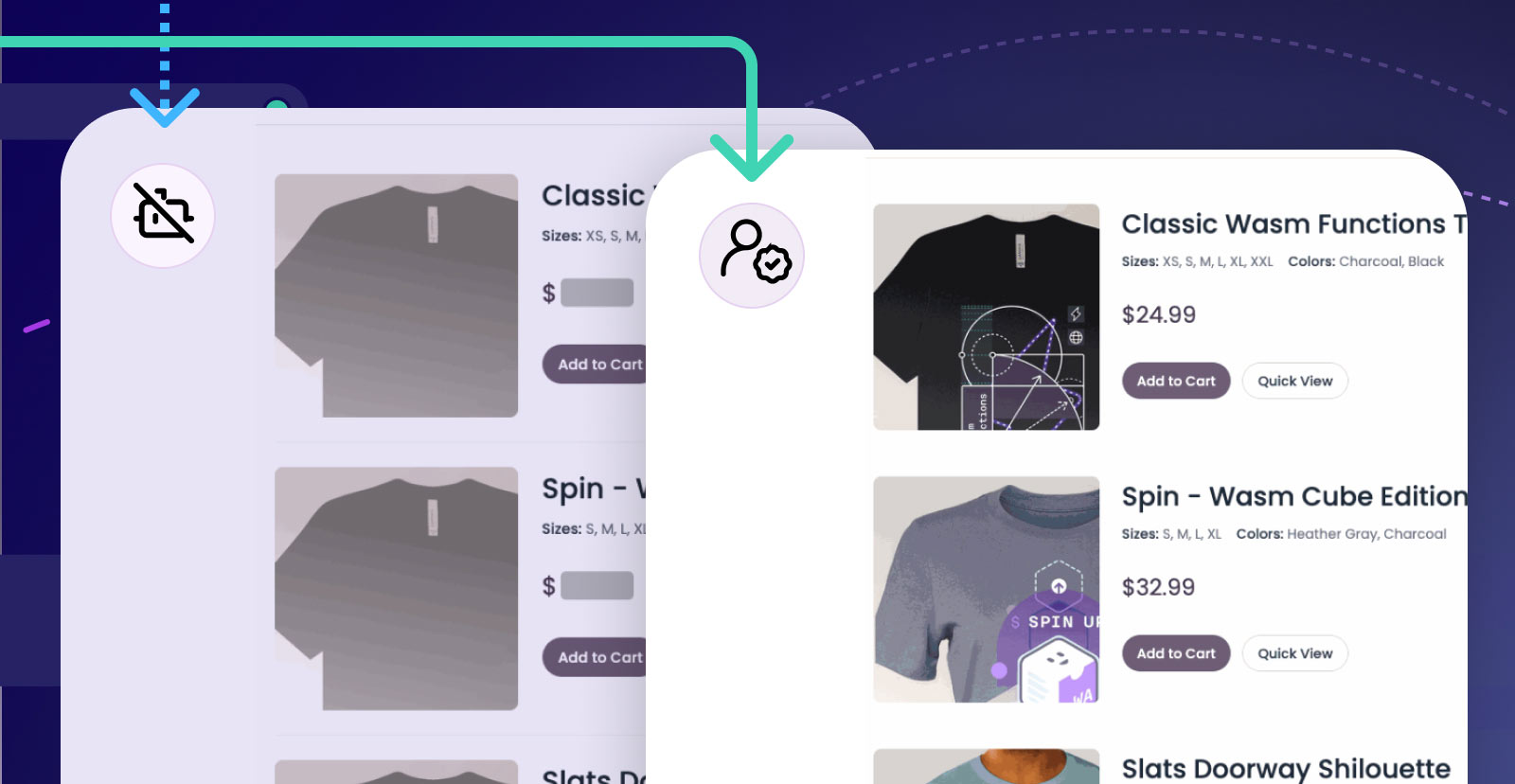
In the world of e-commerce, it is not uncommon for competitors (particularly smaller, less known ones) to crawl big-name sites with the intent of undercutting prices. From automotive to clothes to food to tools, we’ve heard this story across a wide array of e-commerce stores.
Bots crawl a site, looking to link identifiers like ISBNs or makes/models/years to specific pricing information. With this data, the bot owner can then generate competitive listings that are just a little bit cheaper. Ultimately, they hope to show up first or in a prominent position when potential buyers search for deals on big search engines.
AI Content Aggregators
Training models is big business. And from the largest technology companies myriad tech startups, bots are used to scour the internet for text, images, or other media to feed a model training algorithm.
Many organizations spend considerable resources to generate unique human-created content. These organizations would prefer that their content not be ingested into systems that then enable others to create derivative content. For example, an artist may prefer that their work not be used to train an image generating model that can then produce a look-alike work.
But there’s an even more complex and interesting case.
In some cases, a creator may want an AI model to know about them, and recognize them as an authoritative source, but without necessarily allowing the AI bot to use their intellectual property as a training source.
In this case, merely blocking a bot is not the desired end. Some sort of tradeoff must be made between retaining a voice of authority while not giving up one’s intellectual property to be mimicked by an AI.
Intercepting Bots at the Edge
One of the more interesting challenges we’ve fielded recently is how to intercept bots at the edge and dynamically rewrite content to thwart crawlers or feed AI training bots the appropriate data.
The solution we’ve found is twofold:
- Identify which agents are bots, and which are humans
- Let humans go on to the origin while proxying the bots through a rewritter
What we learned early on is that identifying bots requires a lot more than some simple user agent sniffing. Bots are often (intentionally or unintentionally) deceptive about who they are.
There are, however, services that can do this classification. Akamai’s Bot Manager is one such example. It will assign a probability score to any inbound request, and allow customers the ability to pass humans straight through to the origin while undetectably redirecting bots to another origin. In our case, we can use this tool to redirect users to a Fermyon Wasm Function that acts as a rewriting proxy.
A Rewriting Proxy
We created a Fermyon Wasm Function that acts as a transparent rewriting proxy. The goal was to build a content rewriting engine that runs dynamically on the edge (with caching). It serves two purposes: offload bot traffic from upstream and consistently serve redacted content to that bot traffic.

Because we know the upstream will be changing frequently (as, for example, new items are added to a catalog), we want to dynamically rewrite pages, but keep the redacted content cached at the edge for some period of time.
Crawlers typically operate on web pages, so we took the approach that rewriting should happen predominantly in HTML. And that gave us a clean approach: We could use CSS-style rules to target a particular portion of a page, and have the rewriter replace the content identified by that rule.
For example, if we are redacting price, we might target a <div class="price"> element and replace its contents. And we could identify that using a CSS-style selector like div.price.
So the proxy function receives a request from a bot, loads the upstream HTML, traverses the DOM tree using the CSS selector, and then runs a custom replacement function (maybe just a regex or hard-coded value) to replace the desired HTML chunk. Then the redacted HTML is sent back to the bot and cached. If the bot (or another bot) pings back in the next day or so, it will be served the cached HTML, thus reducing upstream load.
For simple cases, then, all we need to do is write replacement rules that pair a CSS-style selector with a replacement string.
But what about cases where we don’t merely want to do simple content replacement, but instead want to dynamically rewrite it?
AI versus AI
Earlier, I mentioned how AI bots train on website text and media. This presents a double-edged sword for those who want to protect their intellectual property while still having the upstream AI recognize their content as authoritative in a domain.
One solution is to use AI to generate content designed to be ingested by an AI crawler or training bot.
For example, say you have a site of short stories. Instead of allowing the AI agent to train on your short stories, you’d like to feed that bot a summary of your story (while letting real humans read the original story).
To do that, we can augment our proxy to use an LLM to dynamically rewrite content for bots. For example, on bot detection, the proxy reads the upstream HTML, uses the CSS rule to identify the chunk of content to be rewritten (instead of merely replaced or redacted) and then feed that parcel of content to an LLM with a prompt to summarize it.
Then the summary is re-inserted into the HTML and fed back to the upstream bot. Since we can cache the content, repeated crawls are both fast and consistent over time.
In our experimentations, we’ve used a smaller LLaMa model running on Akamai Cloud GPUs to do the transformation.
Conclusion
On today’s web, there are more bots than humans. And many of them are misusing your site’s content to gain a competitive advantage or use your data to train AI models.
By combining bot detection with a dynamic rewriting proxy, it is possible to both thwart the undesirable behaviors of these bots while still making sure your content is indexed and your site’s authority is preserved.