Rethinking Microservices


Microservices are serving us well in many ways. But in some ways, we can do better. Having learned a bit from Functions as a Service, containers, and now WebAssembly, we can rethink some of our assumptions and perhaps devise a better way for creating microservices.
In our first blog post, we talked about how we envision a new iteration of microservices. Then we introduced our CMS system, which in many ways exemplifies our approach to microservices. Last week we answered the question, How should we think about WebAssembly?, discussing why WebAssembly is a promising cloud technology. Here, we spell out the problems with microservices v1, and pave the way for a microsevices v2.
Reinventing (and then maintaining) the wheel
If we were to begin with a functional definition of microservices, we would likely tout the model as building REST services that communicate over a network.
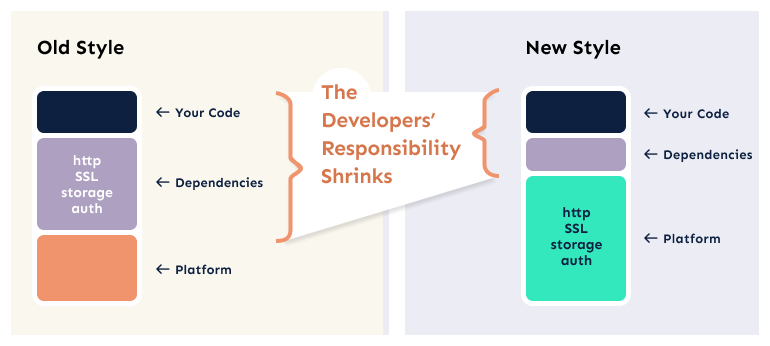
But when it comes to writing microservices, the stark reality is that the first step of creating a microservice involves a massive amount of code. The truth is, we’ve stopped thinking about this, justifying the existence of this code as “framework” without considering the impact it has on overhead, runtime requirements, security, cost, and maintainability.
When we start writing a new microservice, step one is to import gobs of code, spread over hundreds of different packages. Installing the minimalist Node.js microservice framework ExpressJS fetches 100 dependencies. That’s 100 upstream libraries before we can even write “Hello World”. Sum up the dependencies, and the starting point before we have begun coding is 54,000 lines of code. And that’s for a minimalist framework. If we add in an MVC layer like Locomotive, our starting code weight jumps to almost 220,000 lines of code. (This situation is not specific to JavaScript or Node.js. Similar patterns abound in most languages.)
Based on this, we then go on to layer our “business logic” on top of a framework. Compared to the tens or even hundreds of thousands of lines of code with which we start, our business logic (coming in at a few thousand lines of code) is usually just a thin veneer on top of these dependencies.
In the next section, we’ll talk about the security implications of that. But for now, let’s focus on the runtime story. To run a microservice, we need to start with an HTTP server. This server will run only one microservice (thus the name). And the HTTP server needs to be running all of the time. In production, we should really be scaling to multiple instances so that we can handle failure cases and load spikes.
Now there are some cost considerations to keep in mind. The weight of our code will partially determine what compute resources we need. The larger the codebase, the more memory and storage… and ultimately the more CPU. In today’s cloud world, that translates directly to the size of the compute units we need. Then given our base need per compute instance, we need to multiply it by the number of replicas we need to run (usually somewhere between two and five).
Given the average traffic of a microservice for the average application (not things like Facebook, but things like we’re all likely to run), we are paying to keep a full application running all of the time in a replicated way even when it’s idle most of the time.
This is all overhead. And it’s overhead introduced by an assumption that has gone unchallenged: That every microservice needs to be a webserver. Or, to put it more specifically, that every microservice needs to contain, as part of its codebase, a webserver. This is not necessary, and it’s an assumption that should be thrown out.
But wait! Doesn’t Kubernetes solve the runtime problem for us? After all, this was the promise of Kubernetes. Instead of running one microservice per VM, we would run some hefty VMs and have Kubernetes distribute load out to them. There have been many analyses of the false economy of Kubernetes, such as Koyeb’s critique of Kubernetes’ cost, Harness’ analysis of the wastefulness of Kubernetes or the Register’s summary of CNCF’s own spend report. Kubernetes has not shown that its core value proposition is in reducing cloud cost. We could debate the intricacies of that, but instead let’s look at the obvious issue that Kubernetes does not (and cannot) address: It is still the case that if we run our microservices on Kubernetes, we need to reserve enough compute power (CPU, storage, memory, network bandwidth…) to keep all these microservices running all the time, whether they are receiving requests or not.
If we are interested in being economical, if we are interested in saving money when we run in production – even if we’re just interested in consuming less CPU and memory – then it is time to challenge the idea that every microservice should begin with hundreds of thousands of lines of imported code.
But before heading down the path of understanding what this means, let’s look at one other hidden cost that we have just automatically accepted. We’ll talk about it in terms of security, though we could just as easily talk about it in terms of developer stress.
Security can be easier
Your microservice starts with somewhere between fifty and one hundred dependencies. Many of these are transitive, meaning that you do not work directly with them. They are dependencies of other dependencies.
Before you write your very first line of code, you have inherited security debt.
How so? Each time a vulnerability is exposed in one of those libraries, whose job is it to upgrade? And if a zero-day exploit occurs, whose job is it to take preventative measures while the upstream library is fixed? It’s ours – the ones who are writing the application on top of those dependencies.
In the traditional microservice architecture, we take responsibility as developers for the operational aspects of security.
Now, as long as we’re importing code from other sources, this problem will exist. And we certainly gain a lot by using other libraries. In a sense, then, we have to accept that security of dependencies, which manifests as an operational concern, will always become a developer concern because we’re the ones who have to fix it.
But we can definitely reduce the risk. And we can reduce it on the most critical layer of the stack.
In the current microservice architecture, our code includes the HTTP server, the TLS implementation, the host runtime code, the system interfaces, and other low level concerns. On top of that, because our code is run as a process on the host operating system, we developers also inherit responsibility for process security (e.g. permissions). And in a very real way, these are the pieces of the model that are most sensitive when a security issue arises.
To put it another way, breaking out of a process, hijacking SSL, or accessing system files often present the most serious security flaws. And in the current microservice model, we trust external libraries to handle this for us, and we copy those libraries into our own codebase… and then we (as developers) take responsibility for responding whenever there is a vulnerability. And we do this with the most critical parts of our stack.
Do we need to take responsibility for this part of the stack? It is not clear that we do.
A better way to do microservices
Microservices have done a lot of good. We break down our complex workflows into more manageable chunks. We think properly about separation of concerns. And in turn, we keep the cognitive overhead of any given unit relatively low. All of this is excellent, and we as developers are well served.
The problems we saw above were, in comparison, “low level” problems—problems with the technologies choices that we make automatically, and which we largely ignore.
We can find a hint of an alternative, though, by looking at the Functions-as-a-Service (FaaS) model first made popular by Amazon’s Lambda. FaaS promised that instead of writing a server, we could just write a handler function. That function would be triggered (executed) when input was received, and would only run until it could produce output to be sent back.
This model is really compelling because there is little “lower level” code to manage.
FaaS has had its share of problems, largely stemming from two facts: First, FaaS implementations are intentionally platform-bound. Amazon’s FaaS works differently than Azure’s, and so on. Second, FaaS is limited in what it can do, and limited because the platform imposes constraints. We don’t necessarily need to dive into the details, and can instead make the surface observation that because of these limitations, FaaS use has been fairly limited when compared to microservices.
What if we took the strong points of FaaS and ported them over to the microservice model? Could we build a better foundation for microservice architecture?
If we take a look at popular web frameworks, the top level pattern is pretty standard: Map routing to handler functions. For the most part, there is nothing “beneath that” that is truly a developer concern. We might need to configure a few things, like host name or port number. But it is rare that one starts with a framework and then needs to spend time tinkering with HTTP or TLS implementations.
From there, there is additive weight (middleware, databases, specialized libraries). And we definitely want to preserve that.
The logical place, therefore, for a next-generation microservice platform would be to eliminate the base dependencies whose job is just to run the HTTP server, the TLS, the process management, and the basic routing.
Writing a new application would begin with mapping routes to handler functions, not standing up a web server. Ideally, the security boundary for our application would be right here. We would be responsible for the security of our code and any new dependencies we bring in. But the platform would maintain the lower levels, which makes upgrading an operational concern, not a developer concern. Most importantly, what that means is that an SSL patch (for example) does not require you to rebuild, re-test, and redistribute your application. Instead, all that needs to be done is upgrading the host runtime, which can usually be done with no developer iterations.
Like the FaaS model, code written this way can be “scaled to zero.” That is, when your code is not handling a request, it is not running. The underlying platform will always be there listening for new HTTP requests. But with the security boundary at the request handling method, this means that multiple applications can all use the same HTTP listener, which in turn means that we could achieve much higher density. And in this case, that directly translates to compute requirements.
We do have to do some architectural thinking, though. Because in this model, the startup speed of our application suddenly is critical. We need it in the microseconds to low milliseconds (whereas container-based services tend toward 15-120 seconds). And while we’ve all paid lip service to “stateless microservices“, this would be a for-real requirement now. There’s no way to smuggle state into a few global variables tucked away in the corner.
We have the technology!
The major boon of the container ecosystem (and the VM ecosystem before it) was the isolation. VMs gave us a hefty but useful way of isolating a workload. And containers came along and refined it again for us. Above, we just discussed the idea that it would be great to reduce the code weight of our microservices by essentially factoring out the web server.
Can we still achieve the level of isolation that we desire? The answer is yes, because the answer is WebAssembly.
Originally, WebAssembly was intended as a browser runtime, a step beyond JavaScript, and a better way of doing what Java Applets and ActiveX once tried to do. But it turns out that the browser sandbox model is precisely the kind of sandbox model we desire in this present situation. The runtime distrusts (and sandboxes) the binary. But through a capabilities model, it selectively provides features to sandboxed code. Startup speed is paramount. Users don’t like slow websites. Also, the architecture and operating system of the host don’t need to match the host and OS of the developer—again, a virtue for cloud computing. And the WebAssembly format was designed as a compile target for many programming languages.
This is what we want for a new iteration on microservices. We can write our HTTP handlers in whatever language we want (Rust, C, JavaScript, Python, and the list keeps growing), then compile it to WebAssembly. The host runtime will provide the features necessary, such as a filesystem (a highly sandboxed one), outbound HTTP, key/value storage, etc.
We can focus our microservices on handling discrete problems very well. And the underlying platform can manage all of the HTTP, SSL/TLS, and so on.
At Fermyon, we are working on just such a platform, combined with a set of pluggable components which will safely provide the capabilities that microservices need. And along the way, we are discovering some additional advantages of working this way.
Standard instrumentation
When the web server is externalized, and when we can inject components as capabilities into the runtime, we gain some advantages when it comes to instrumenting code. And these advantages manifest as improvements to the debugging, diagnostic, and monitoring aspects of running code.
For example, we can begin by providing standardized metrics and logging. And we can bake this into the platform. Thus, per-request timing is instantly available with no development work, as are uptime, liveness, and failure reporting. All of this requires zero development because it is a platform feature.
Even better, when you start logging in your app, the platform can transform log messages into the structured format log analyzers prefer. And this information is nestled in with the broader platform logging. The desirable outcome, then, is that one of the more mundane (and by that, we mean boring) chores that we as developers used to do has now been taken care of by the platform. But we still get all of the benefits: easy log analysis and rich metrics.
For those times when a developer wants to be a little more particular, the platform can make metrics and logging components available to the WebAssembly binaries. And in those cases, developers will be able to easily insert metrics data (in the form of a function call in the module) and have that information sent straight into the platform metrics tool. The goal here isn’t so much to make the complex simple as to make the boring invisible (or only visible in those moments you care about it).
Externalizing implementation details and data services
Sometimes we care whether our key/value store is Redis. Other times we don’t. The Fermyon platform makes it possible for the developer to decide. And it provides the guarantee that for some features – key/value storage, object storage, file system, environment variables, and so on – the platform will always provide an implementation (even if the developer doesn’t need to know the particulars of that implementation). Local development may use just flat files. A server version may use Redis, Minio, and NFS. A cloud version may use hosted versions, which would vary between AWS, Azure, and DigitalOcean (or whatever cloud provider you care about). But to the developer, the APIs are the same. Call a function to set a key and value. Call another function to give a key and get a value. Implementation details are irrelevant so long as the core feature works as expected.
WebAssembly’s component model makes this possible, and does not require peculiar layers of indirection or external services. Rather, at startup time the WebAssembly runtime selects the right components that satisfy the interface requirements specified by the developer. Object oriented developers might think of this using interface/class terminology, but the critical difference here is that selecting the implementation of an interface is an aspect of the runtime, not part of the developer’s code.
The possibilities here may help us push our understanding of microservices one more step, into revisiting our assumptions about distributed computing.
Pushing distributed computing one step further
Let’s rewind about ten years. “Distributed computing” was the 400-level class that we took in our last year of computer science. Then we kept the textbook as a badge of honor. A sign that “I suffered through it.” A medal of honor.
In practice, distributed computing was messy. Our monolithic apps were clumsy in that regard.
But a few changes happened. Containers became a thing. Languages like Go borrowed heavily from distributed computing concepts like CSP. And more importantly, the microservice architecture challenged both the assumption that distributed computing was hard, and our corresponding assumptions about how it should be done.
The old dogma faded. And we began to look at distributed computing as a problem that could be solved with a combination of small and narrowly focused webservices, REST-ful applications, and devotion to stateless computing. Kubernetes offered an orchestration framework for deploying microservice architectures (in a way that emphasized statelessness).
Distributed computing didn’t seem so lofty a goal. But the architectural decisions that developers needed to make were thrust into the limelight. We were required to think hard about how our microservices should be structured in order to achieve the right network topology.
In an interesting way, while Go was building CSP into the language, Kubernetes was building CSP into the infrastructure. And developers had to think about the same pattern on two different levels of abstraction.
WebAssembly might offer us another way to achieve distributed computing, but in a way that reduces the cognitive overhead for developing distributed applications. And the component model is what makes this so.
In the previous section, we looked at components as a way to graft external services (like key/value storage, logging, and metrics) into our microservices. But what are these components? We didn’t really talk about that. Because the important bit was that the interface definitions made the actual implementation details irrelevant to the developer.
Some of those implementations are, in fact, features of the underlying host runtime. These features are hooked into the WebAssembly binary (the guest binary) at runtime.
But other implementations are not part of the host runtime at all. They’re just other WebAssembly modules that are linked at startup. In this way, they feel (to the developer) like a library. But they are executed (on the platform) as a separate WebAssembly module. They have their own memory space, and it’s cordoned off from the developer’s code. When the developer interacts with this external component, it feels like a function call, but acts more like an RPC.
And that’s where distributed computing gets interesting.
Because the runtime, not the developer, handles the distribution of computing. As far as the developer is concerned, it’s just a function call to a library. The runtime may choose to run that component right there, adjacent to the developer’s code. Or it might run the code on another compute instance in the same datacenter… or another datacenter… or on the edge… or on a 5G tower… or somewhere else altogether. The exact location of that execution is not a developer’s concern. The developer’s only concern is that the right function is executed safely and reliably.
Distributed computing is no longer the stuff of high-level university courses. Nor, strictly speaking, is it relegated to complex topologies of “microservices v1.” It’s an implementation detail of the new way of writing microservices.
Conclusion
Microservice architecture has been a major boon to cloud-centered development. That much is indisputable. Virtual machines opened the possibility of microservice architectures. In a second wave, the container ecosystem codified distributed computing with microservices as the “new normal” for cloud computing. We hit some difficulties along the way. And this caused us to pause and rethink some assumptions—assumptions about security, about design, and about working with external services.
As we rethink these assumptions, we can see the possibilities that WebAssembly brings to the table. We can reduce the amount of developer time spent on security at critical layers. And we can reduce the amount of code weight that the microservice developer must take responsibility for. At the same time, we can improve logging and metrics while simplifying the process of managing external services. And the same mechanism that provides these advantages—the WebAssembly component model—offers us a compelling version of the future of distributed computing.
It’s a good time to be a microservice developer. Because the future is bright.




