Bringing AI to the Edge with WebAssembly - OpenInfra Korea 2025
 Brandon Kang
Brandon Kang
fermyon
akamai
openinfra
spin

Hi everyone! I’m Brandon Kang, Principal Technical Solutions Architect at Akamai Technologies, and have been collaborating with Fermyon around WebAssembly and cloud-native projects. Through this post, I’d like to share my session presented at OpenInfra Days Korea 2025.
OpenInfra Days Korea is one of the most influential open-source infrastructure conferences in Asia, bringing together developers, architects, and researchers to share how cloud-native technologies evolve in real-world environments. In Korea, this event has a special significance: it highlights the country’s rapidly growing cloud ecosystem while connecting local innovation to the global OpenInfra community.

At this year’s OpenInfra Days Korea 2025, I had the opportunity to present a session titled “Inference Anywhere – Deploying Edge AI with WebAssembly on Kubernetes”. The session explored how WebAssembly and AI inference applications can work together to accelerate AI inference at the edge, dramatically reducing latency while maintaining portability and security.
The Session: Wasm for Fast AI Inference at the Edge
The talk focused on combining WebAssembly with Kubernetes and GPU acceleration to deliver inference services closer to end users. Instead of relying on large regional data centers that often introduce significant latency, we can deploy Wasm workloads in edge locations just a few kilometers away from the user.

By leveraging SpinKube, a sub-project of CNCF’s Spin framework with Kubernetes, developers can run Wasm applications seamlessly in a cluster environment as Kubernetes-native resources. In my demo, a Spin component received an HTTP request, called an AI inference API via Ollama and returned results within milliseconds, all implemented in just a few lines of Rust. This architecture demonstrates how Wasm’s sandboxed execution and near-native performance can enable AI inference pipelines that are both lightweight and secure.
Fermyon Wasm Functions on Akamai: Fast Runtime Meets Edge Network
This work builds directly on the collaboration between Fermyon and Akamai. As announced in Fermyon’s blog, Wasm Functions can now be deployed across Akamai’s massively distributed edge network. This means developers can package lightweight Wasm services and run them in hundreds of edge locations worldwide, achieving cold start times in the sub-millisecond range.
When combined with AI inference including GPU acceleration, this approach unlocks a powerful model. The result is a user experience that feels real-time, even for AI-powered applications such as image recognition, natural language inference, or recommendation systems.
Why “Fast Runtime Meets Edge Network” Matters
In AI workloads, milliseconds matter. A 200 ms delay in a cloud region may seem negligible, but for applications like real-time gaming, IoT analytics, or autonomous systems, it can mean the difference between usable and unusable. Wasm’s near-native performance and security isolation make it ideal for running trusted workloads at the edge, while Akamai’s network ensures global reach and low-latency delivery.
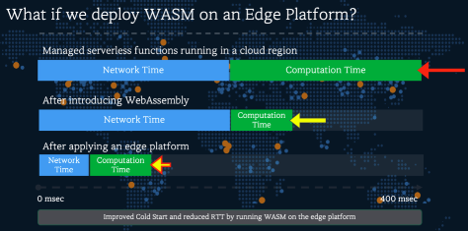
The convergence of fast runtimes(Wasm) and edge networks(Akamai) addresses three critical challenges:
- Latency: Bringing inference closer to users avoids round-trip delays
- Portability: Wasm modules run consistently across heterogeneous environments
- Security: Sandboxed execution reduces the attack surface in multi-tenant deployments.
Looking Ahead: The Future of Wasm and AI at the Edge
The ecosystem around WebAssembly is evolving quickly. Standards like WASI-NN and WebGPU are expanding Wasm’s ability to access GPUs and accelerators directly, while CNCF projects such as WasmEdge and SpinKube are maturing integration with cloud-native platforms. Over the next few years, we can expect:
- Broader GPU/TPU/VPU integration through Wasm runtimes
- Unified developer experience where building, testing, and deploying Wasm apps is as seamless as containers today
- Enterprise adoption of Wasm at the edge for security-sensitive and latency-critical workloads.
In short, Wasm is emerging as a foundational runtime for the next generation of distributed AI services. When combined with GPUs and delivered through global edge platforms, it creates the infrastructure needed for true “inference anywhere.”
Conclusion
OpenInfra Days Korea 2025 provided a platform to showcase how Wasm, GPUs, and Kubernetes converge to redefine AI inference at the edge. The partnership between Fermyon and Akamai exemplifies this vision - combining Wasm’s fast, secure runtime with the world’s largest edge network.
As AI continues to move from centralized training to distributed inference, the future will belong to platforms that can deliver fast, portable, and secure execution environments - anywhere users are.
If you’d like to explore this further, I encourage you to try out SpinKube and see how easy it is to run Wasm applications on Kubernetes. I’ll also be sharing more talks and demos on GPU orchestration and WebAssembly at upcoming cloud-native events - stay tuned!