AI at The Edge With Fermyon Wasm Functions
 MacKenzie Adam
MacKenzie Adam
spin
ai
Fermyon Wasm Functions

Let’s start off this post with a short exercise in imagination.
It’s your first day at KubeCon. The smell of drip coffee and baked goods greets you, along with hundreds of sponsor booths lining the hallway, staffed with people eager to teach you how their technology can help you build more secure, efficient, and cost-effective software.
It can be an intimidating task, deciding how to split your time between perusing the conference floor, attending the talks most relevant to your interests, and making all those coffee chats you lined up before the event.
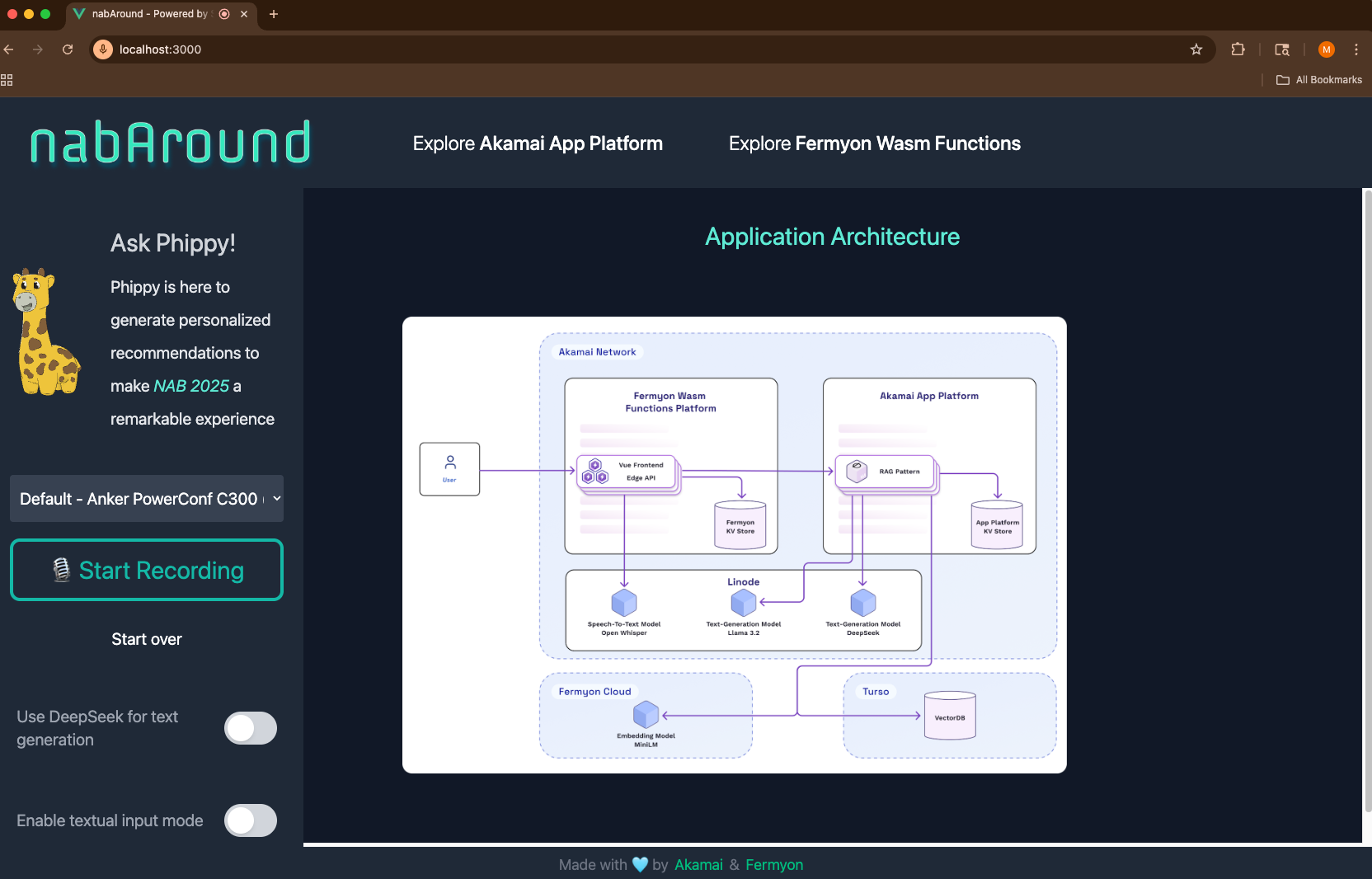
To take one task off your plate, we built KubeAround, an AI-powered scheduling assistant for conferences. Instead of manually sifting through the talk schedule (there were 229 sessions at KubeCon + CloudNativeCon Europe 2025!), you can simply ask KubeAround (via voice or text) to find the best sessions for your interests and availability. And it responds in milliseconds.
Try it live: KubeCon Japan Demo
How It Works
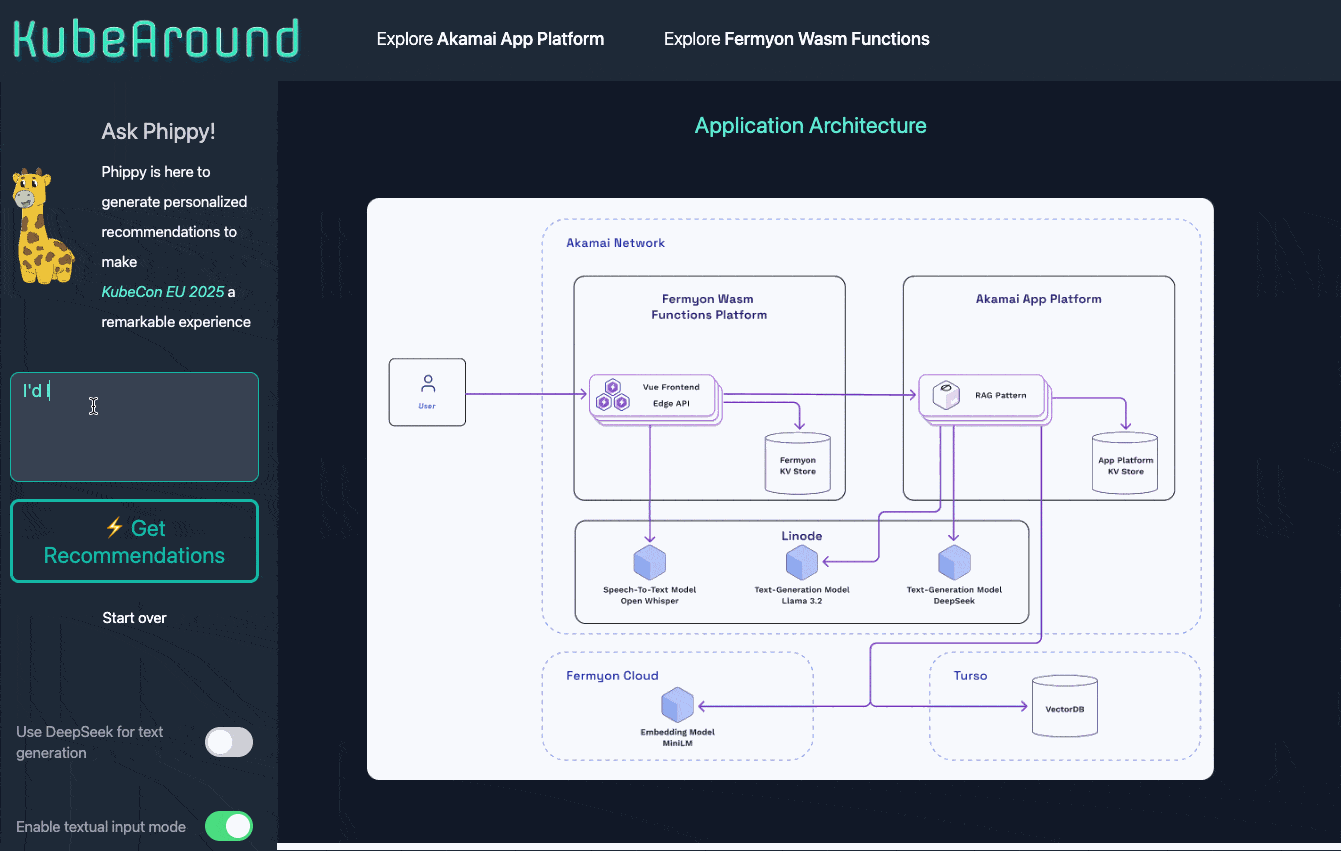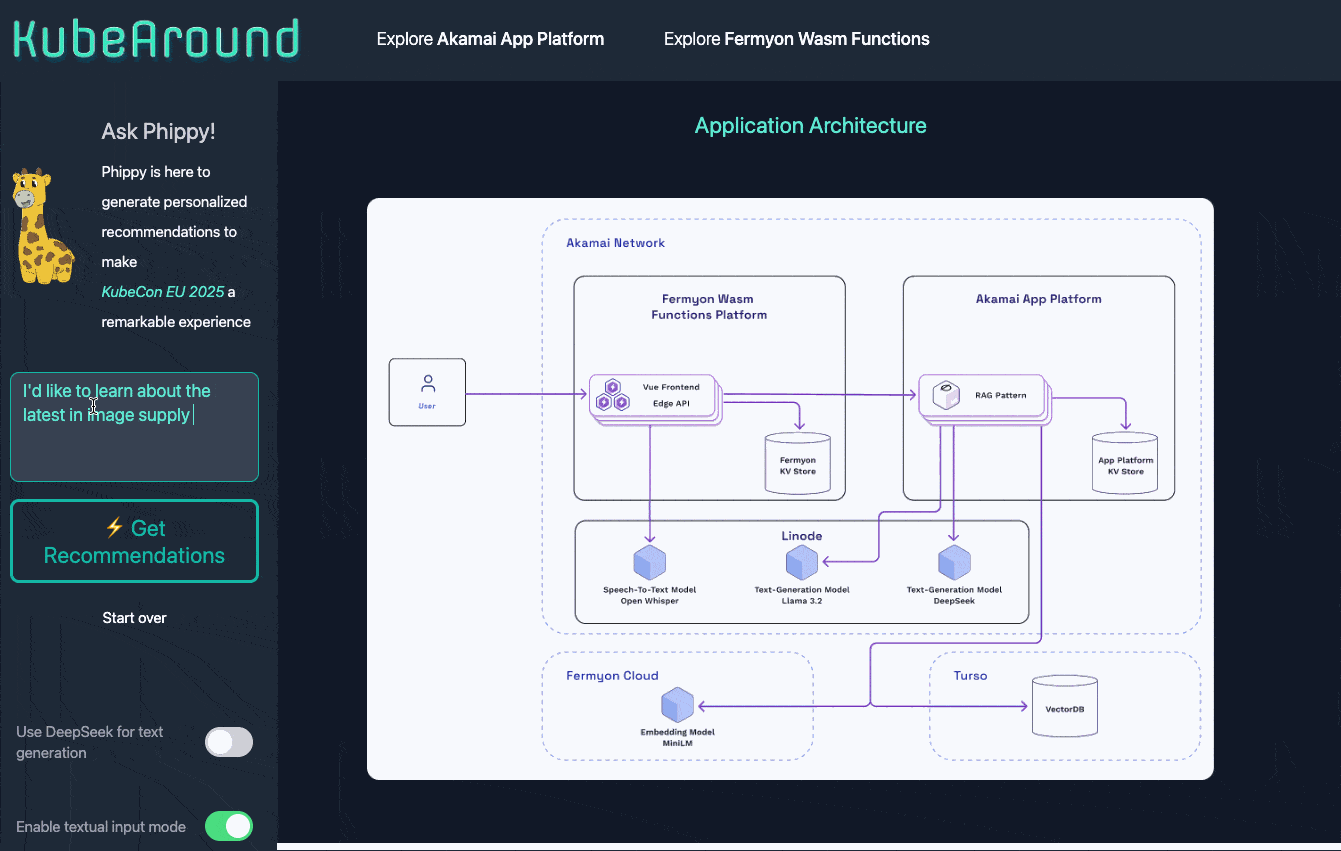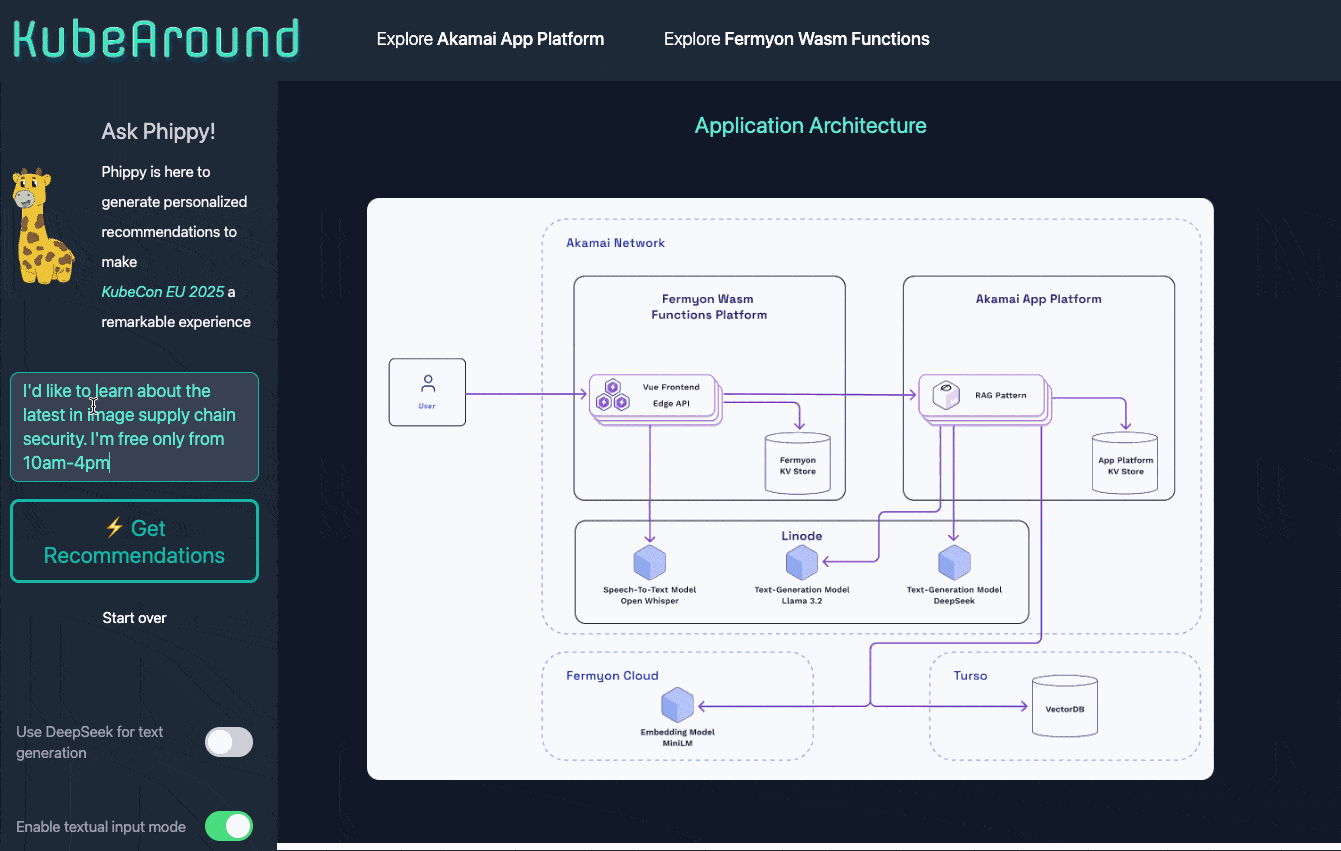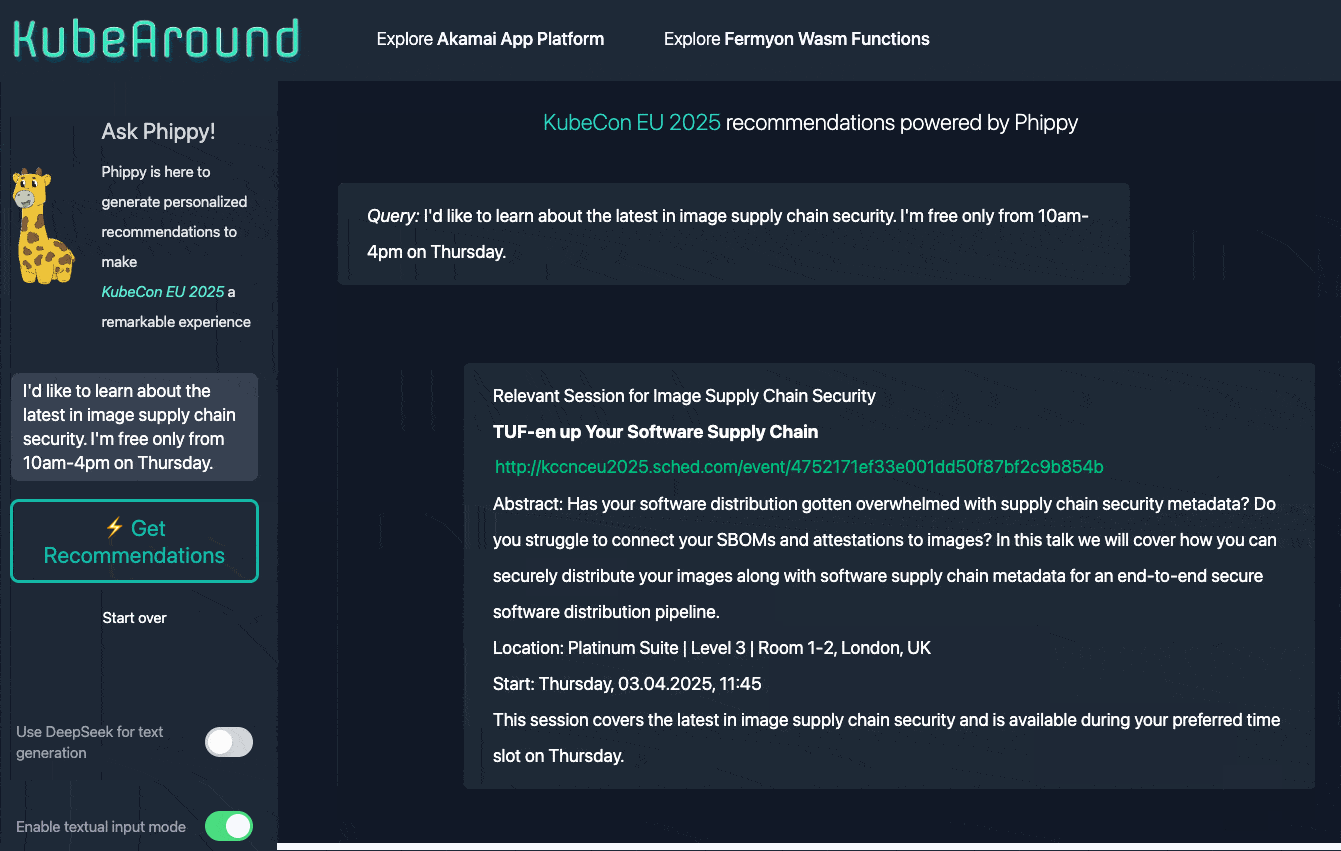
Under the hood, KubeAround is composed of several key parts:
- Frontend, Edge-API & Key-Value Store deployed globally using Fermyon Wasm Functions
- A centralized API implementing the Retrieval-Augmented Generation (RAG) pattern along with a central cache hosted on Akamai App Platform via open-source SpinKube
- Multiple LLMs hosted on GPU-backed Linode instances
- A vector database powered by Turso
- Embedding Models powered by Fermyon Cloud to compute vectors
Let’s dive into how these services work together to deliver a fast, secure, and delightful experience for both users and developers.
Globally Distributed Frontend, Edge-API and Key-Value Store
The frontend and Edge API are bundled into a single Spin application and deployed globally via the Fermyon Wasm Functions spin aka plugin. This gives us low-latency compute and fast content delivery at the edge. Leveraging the NoOps Key-Value Store provided by Fermyon Wasm Functions, we can generate recommendations for known questions in no-time.
Frontend Component
We chose Vue.js for its lightweight footprint and reactive data binding, which helps keep the UI fast and responsive. KubeAround’s frontend has a few responsibilites:
- Capture user input (either voice or text)
- Send user input to Edge-API
- Display recommendations streamed from the Edge-API
- Render a simple toggle to A/B test different Large Language Models (LLMs)
Static assets are served via Spin’s static file server template for lightning-fast load times. Here’s a snippet from the application manifest:
[[trigger.http]]
route = "/..."
component = "frontend"
[component.frontend]
source = { url = "https://github.com/fermyon/spin-fileserver/releases/download/v0.3.0/spin_static_fs.wasm", digest = "sha256:ef88708817e107bf49985c7cefe4dd1f199bf26f6727819183d5c996baa3d148" }
files = [{ source = "static", destination = "/" }]
# Build the Vue Frontend when `spin build` is executed
[component.frontend.build]
command = "npm install && npm run build && touch ../static/.gitkeep"
workdir = "frontend"
Spin’s capability-based security model ensures this component can only access the “files” directory, giving us a secure-by-default frontend.
If you’re interesting hosting a static site with Spin, we have plenty of starter templates available on Spin Hub including Jekyll, Zola, Angular, Tera, NextJS, 11ty, Docuusaus, Quik, Hugo, Dioxus.
The Edge-API component
The Edge-API hanldes communication between the frontend and backend services running on Akamai’s App Platform. This component is implemented in Typescript for ease of development, but could have just as easily have been written a performance sensitive language such as Rust thanks to the polyglot capabilities of WebAssembly. The main responsibilities of our Edge-API are to:
- Translate voice input to text by sending it to Open-Whisper running on Linode GPU for transcription
- Take user queries and model selection, check to see if we have a response in the Fermyon Wasm Functions Key Value Store; otherwise forward to our Central API for processing
- Use Response teeing to cache new answers in the Edge Key-Value store and stream them to the frontend in parallel
Within the application manifest, you can see our Edge-API has been granted the necessary capabilities required to complete these responsibilites:
[[trigger.http]]
route = "/api/..."
component = "api"
[component.api]
source = "api/dist/api.wasm"
# We use Key Value Store to cache recurring questions
key_value_stores = ["default"]
# Allow outbound connectivity to the central api running on Akamai App Platform
allowed_outbound_hosts = ["{{ central_api_endpoint }}"]
[component.api.build]
command = "npm install && npm run build"
workdir = "api"
Unlike the frontend component, our Edge-API component must have access to a Fermyon Wasm Functions Key Value store to pull in cached user queries and answers to deliver latency-sentitive data to our users. In the event we have a cache miss, it has permission to make outbound calls to the central-API for updated response.
Test Locally and Deploy Globally
KubeAround has been designed as a modular system, meaning we can independently test our frontend and edge-API components. To do so, we’ll run the spin build command:
$ spin build
Building component frontend with `npm install && npm run build && touch ../static/.gitkeep`
Working directory: "./frontend"
< ... >
loaded configuration for: [ '@fermyon/spin-sdk' ]
asset bundle.js 32.7 KiB [emitted] [javascript module] (name: main)
orphan modules 44.3 KiB [orphan] 29 modules
runtime modules 396 bytes 2 modules
./src/index.ts + 11 modules 31.6 KiB [not cacheable] [built] [code generated]
webpack 5.98.0 compiled successfully in 633 ms
Using user-provided wit in: /PATH/knitwit
Component successfully written.
Finished building all Spin components
And then serve it locally with spin up:
$ spin up
Logging component stdio to ".spin/logs/"
Storing default key-value data to ".spin/sqlite_key_value.db".
Preparing Wasm modules is taking a few seconds...
Serving http://127.0.0.1:3000
Available Routes:
api: http://127.0.0.1:3000/api (wildcard)
frontend: http://127.0.0.1:3000 (wildcard)
A quick visit to localhost:3000 shows a local copy of our frontend and edge-API running on my machine:
Once we’re ready to move to production, we’ll deploy using the spin aka plugin. When we run the spin aka deploy command, Fermyon Wasm Functions will package our application, store it in a managed OCI registry, and distribute it across all available regions on our behalf.
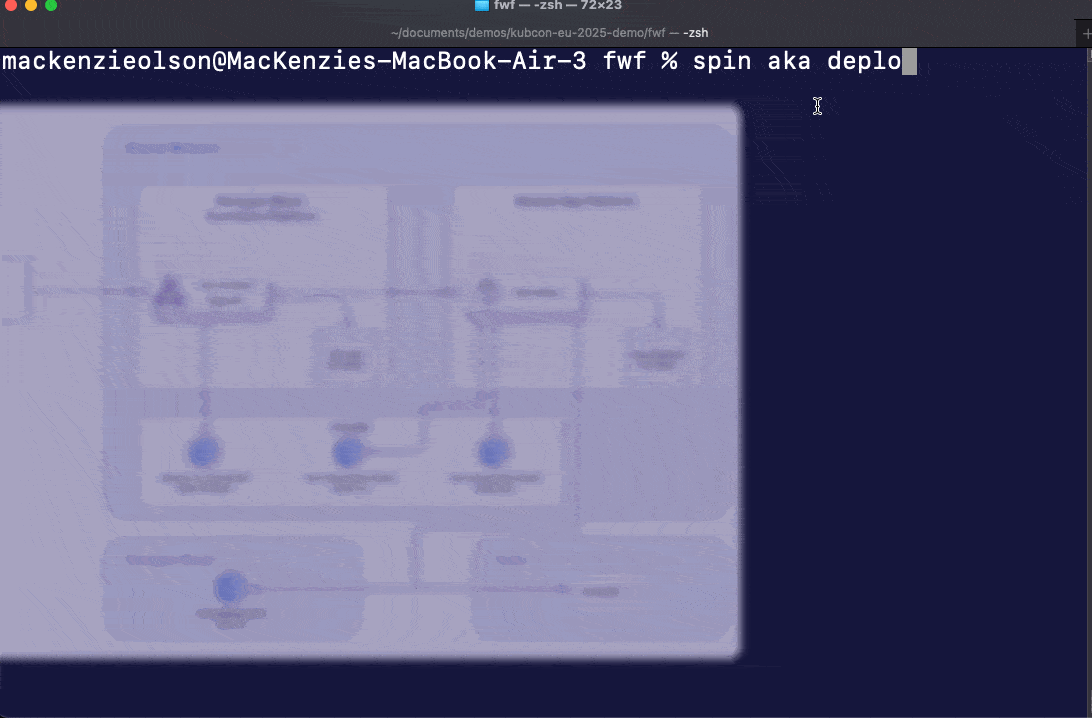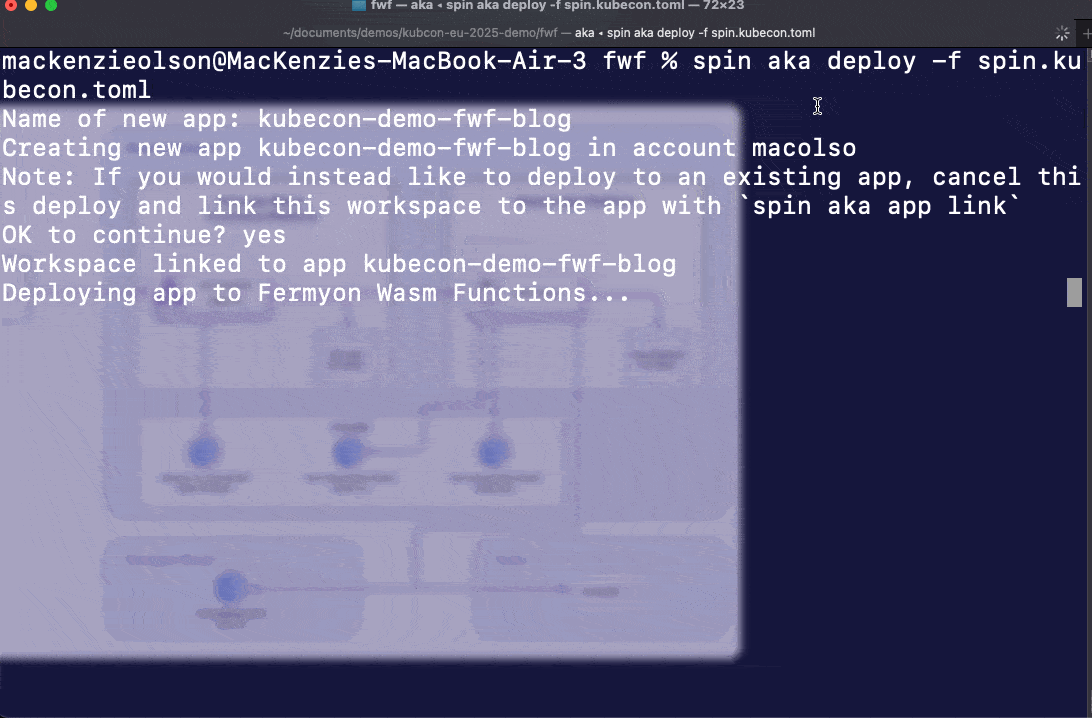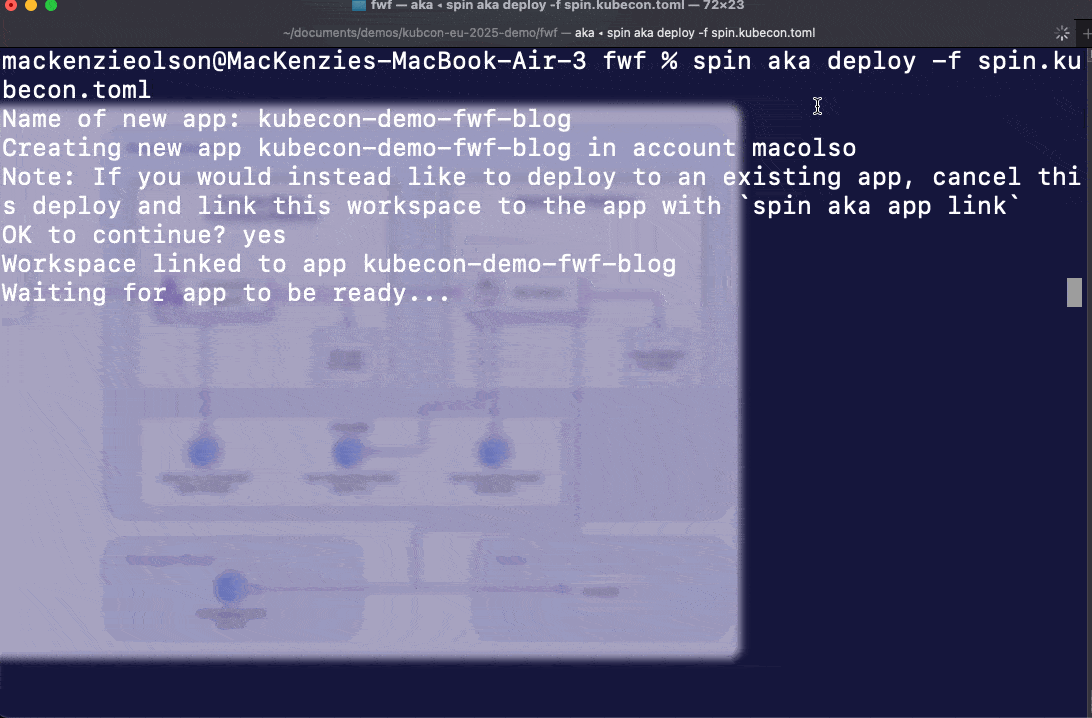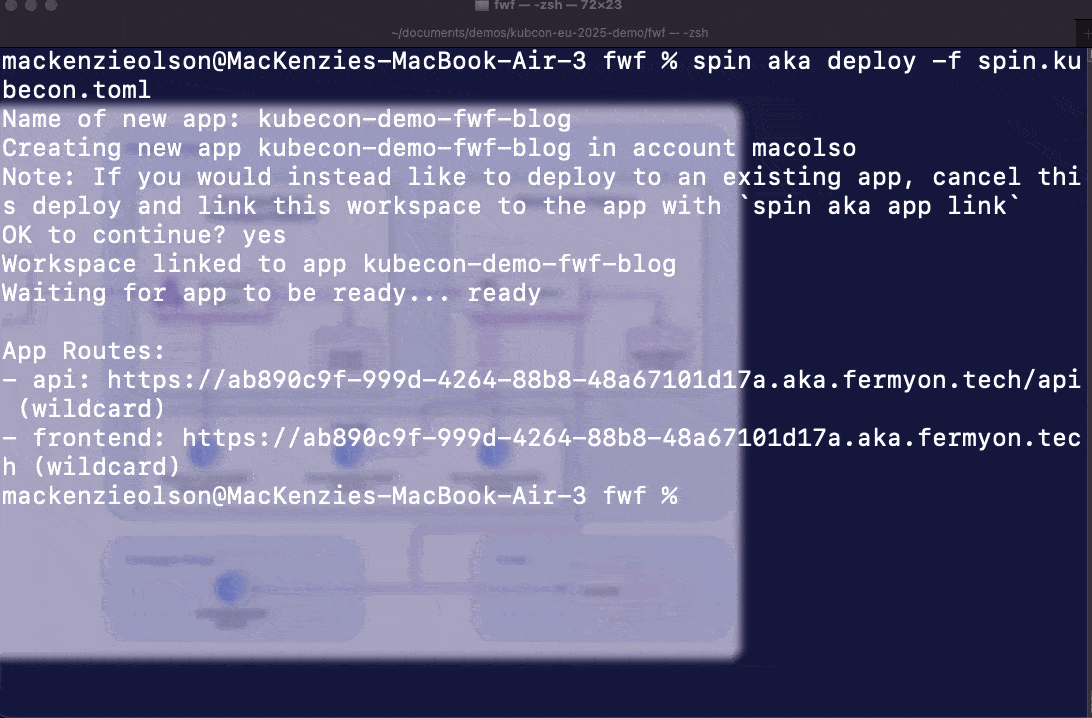
Want to integrate with an existing Akamai property? Check out our Property Manager guide.
Centralized-API
Now we’re going to get into how the sausage session recommendations are made. The centralized-API turns queries into personalized schedule recommendations, leveraging a multi-step process as a Retrevial Augment Generation (RAG) service
A RAG service combines information retrieval with generative models by fetching relevant documents from a data source and using them to ground and enhance the output of an LLM
- Embed sanitized user query using
minilm on Fermyon Cloud GPUs
- Cache sanitized user query embeddings in Valkey for faster future lookups
- Query vector DB (Turso) for the most relevant conference sessions
- Construct a prompt using retrieved results, model-specific instructions, and user preferences
- Send to LLM (Llama 3.2 or DeepSeek on Linode GPUs) for a response
- Stream response back to the Edge API
Our RAG service is implemented as a Spin application, running on Akamai’s App Platform thanks to SpinKube (an OSS project that allows you to run your Spin applications alongside traditional containerized applications on your Kubernetes cluster).
Here we can see the portability benefits in action for Spin. We’re continue to use the same format of application manifest, despite this Spin application running on Kubernetes rather than Fermyon Wasm Function’s managed platform.
A key design principle in this demo is multi-layered caching to improve responsiveness. For instance, the Central API layer includes a Valkey-backed key-value store to prevent repeated queries from being vectorized repeated queries quickly, even across different regions.
With the service’s responsibilties in mind, we can see this application has by far the largest reach as it must connect to our LLMs responsibily for generating user-facing recommendations, LLMs for generated embeddings, vector databases, key-value stores for caches. There are also serveral variables used to adjust the models output, such as similarity search limits and temperature.
[[trigger.http]]
route = "/..."
component = "api"
[component.api]
source = "dist/api.wasm"
exclude_files = ["**/node_modules"]
allowed_outbound_hosts = [
"{{ llama_endpoint }}",
"{{ alternative_model_endpoint }}",
]
# Use Fermyon Cloud to compute embeddings
ai_models = ["all-minilm-l6-v2"]
# Documents (sessions) are stored in a sqlite running on TursoDB
# See runtime configuration file
sqlite_databases = ["default"]
# Embeddings for questions are cached in key value store
# See runtime configuration file
key_value_stores = ["default"]
[component.api.variables]
llama_endpoint = "{{ llama_endpoint }}"
llama_identifier = "{{ llama_identifier }}"
alternative_model_endpoint = "{{ alternative_model_endpoint }}"
alternative_model_identifier = "{{ alternative_model_identifier }}"
similarity_search_limit = "{{ similarity_search_limit }}"
temperature = "{{ temperature }}"
[component.api.build]
command = ["npm install", "npm run build"]
watch = ["src/**/*.ts"]
Putting It All Together
We’ve covered a lot of ground together today—maybe not quite as many steps as you’d take during a week at the KubeCon conference, but close! KubeAround has shown us how distributed edge functions and caches make AI inferencing at the edge not just practical, but surprisingly powerful. For computationally intensive tasks that need to be colocated with a data source (what we affectionately call “heavy-weight functions”), we’ve learned how to host these workloads on Kubernetes clusters (such as the managed ones on Akamai App Platform) using SpinKube. With Akamai Cloud GPUs, deploying your preferred LLM is straightforward—in this demo alone, we ran three different LLMs handling everything from voice-to-text transcription to natural language processing.
If you’re planning on attending KubeCon Japan, swing by the Akamai Booth to see KubeAround in action. Otherwise, we’re around in Discord for all of your Fermyon Wasm Functions questions!