Serverless A2A with Spin
 Matt Butcher
Matt Butcher
spin
fermyon
ai
llm
a2a
In only a few short years, LLMs have gone from a niche technology to the heart of a new wave of AI applications. And even more recently, Model Context Protocol (MCP) has earned buzz by standardizing a way to expose tools to LLMs and reasoning agents. But exposing tools is only a small step in harnessing the power of AI agents. Google recently contributed a new open protocol to Linux Foundation. A2A (short for Agent-to-Agent opens new opportunities for building agentic systems. In this post we’ll see how easy it is to create Spin apps that implement the A2A protocol.
What is an Agent?
In AI parlance, an agent is a piece of code, typically backed by some form of AI, that performs tasks on behalf of a user. As an example, one could envision a travel agent that received a prompt (“Book me a flight and hotel in Chicago next week.”) and then acted on that prompt, returning a response (“Okay, I booked you the following flight and hotel…”). Sometimes agents are conversational. The simple example above would more likely be carried out over a conversational series (“Agent: What part of Chicago would you like to stay in?”, “User: River North or Downtown”). Sometimes they might return parseable data instead of human text. Or sometimes they might produce audio, images, or video.
While agents may do things on behalf of a user, it is not necessarily the case that an agent will directly interact with a user. For example, one recent trend has been to connect agents to GitHub repositories. An agent can perform an action when something in a GitHub repo changes (for example, when an issue is filed or a pull request is created). An agent may be able to complete its job without directly interacting with the GitHub repository owners.
Even more exciting, though, is agent-to-agent communication. In this case, one agent may leverage other agents it knows about in order to achieve a particular result. That’s where A2A comes in.
What is A2A?
A2A is a simple protocol for connecting agents. It has two main functions:
- Agent discovery: Allow agents to discover each other
- Agent interaction: Define how one agent can send messages to, and receive messages from, another agent
The protocol is based on JSON, JSON-RPC, HTTP, and SSE (Server Sent Events), all of which are broadly understood and utilized standards and techniques. This is good news; we can use existing libraries and tools to write our agents.
Let’s take a look at these two parts of the A2A spec.
Discovery with Agent Cards
Many existing Web standards perform discovery by the simplest possible means: Agree on a standard location and standard data format for a basic piece of information. For example, robots.txt files inform web crawlers of how to traverse a site’s content. A file named favicon.ico provides an icon for site. In both of these cases, humans and applications alike can assume both the location and data format for these files.
The A2A specification defines a similar technique for allowing agents to discover each other. A JSON formatted file at /.well-known/agent.json describes the available agent endpoints at a particular server and how those agents can be interacted with.
For this post, I wrote a simple A2A-style agent that uses Gemini to answer ethical questions using one of the major Western moral philosophies (deontology, virtue ethics, and utilitarianism). Here’s what that agent’s card looks like:
{
"name": "The Digital Ethicist",
"description": "This agent analyzes ethical questions based on philopsophical ethics frameworks such as utilitiarism, deontology, or virtue ethics.",
"url": "http://localhost:41241/api",
"provider": {
"organization": "Technosophos"
},
"version": "0.1.0",
"capabilities": {
"streaming": false,
"pushNotifications": false
},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"skill": [
{
"id": "ethics-utilitarian",
"name": "Digitial Utilitarian",
"description": "Address ethical problems and dilemmas using utilitarian approaches.",
"tags": [
"philosophy",
"ethics",
"reasoning",
"morality",
"moral philosophy",
"utilitarianism",
"hedonic calculus"
],
"examples": [
"Is it okay to cross a crosswalk against the light if there are no cars coming?"
]
}
]
}
For the most part, the card format is so intuitive that we can read through the fields and understand the purpose. In a nutshell, though, the card describes what this endpoint can do, and exposes one or more skills. When a client issues a request against this A2A service, it can use the skill ID to inform the endpoint what specific task it is asking the agent to perform. In the example above, one skill is exposed: A utilitarian ethical reasoner. (Utilitarianism is a philosophical system of ethics that determines what is ethical based on how much pleasure or pain is caused by an action.)
Inter-agent Interaction with JSON-RPC
Thanks to the card, humans and agents (and even tools) can all understand what agents we have made available, and what they do. Thanks to the A2A interaction protocol, it is also clear how to interact with our agents.
The JSON-RPC 2.0 specification defines a remote procedure call (RPC) mechanism that defines how a client can request that a service run a function and return the result to the client. We won’t go into this protocol in any detail, but there is one thing specific to A2A that we should cover: The multiple modes of interaction.
The agent card can describe its capabilities. In the example above, there is a section that
"capabilities": {
"streaming": false,
"pushNotifications": false
},
speaking practically, it means that as we write our agents, we have different options for how to construct the interaction between two agents.
- Asynchronous Sessions: Send a request, get a response that includes a session ID. For a follow-up message in the same context, send the session ID. This is a default feature. All A2A servers are expected to implement it.
- Streamed Sessions: Open a stream and send a series of messages back and forth. This technique uses HTTP SSE (Server Sent Events) to keep a stream open and allow the server to initiate events. By setting the
streaming capability to true, we can indicate that we support it.
- Push Notifications: Send a request that includes a notification URL. When the agent is done processing the request, notify via the notification URL. This uses webhooks as a callback mechanism for an agent. We can indicate support for this in the agent card by setting the
pushNotifications capability to true.
Note that the very simplest case, a one-shot question-and-answer, is just a simple use of asynchronous sessions. We’ll build one of those in the next section.
How do you choose which one to use in any given set of circumstances?
Streamed sessions use a long-running network connection to send multiple messages between the client and the server agent. In most cases, asynchronous sessions are better (and I’ll describe why in a moment). But one cases where streamed sessions works very well is when the client side of the communication is not another agent, but is a human who is impatient and wants to see at least the beginning of results as soon as they are available. You can envision the way that many AI-based chats stream back tokens to emulate a user typing on a keyboard.
Streamed sessions are less resource efficient because they consume network and compute resources on both the client and server even when one or both sides are just waiting. SSE logic adds more complexity to application code, and often do no good if the client-side is another agent or tool. There is no reason to keep a network connection open and compute resources allocated while waiting for a client agent to run returned data through its own model, or even contact other agents. This is wasteful in an expensive way.
A2A’s asynchronous mode is a better fit in most cases. In this case, a request is sent to the agent, which sends back a response and then closes the connection. If the client agent then needs to make a follow-up request, it opens a new connection and sends a new request. By sending the session ID provided by the server agent in the last interaction, the client clearly indicates that this is the continuation of an existing session rather than a new session. This mode fits better with the agent-to-agent modeling we’d expect, where a client agent would receive a response, process it through its own logic, and possibly (perhaps seconds, minutes, or even hours later) issue a follow-up request.
This points to an emerging trend. As agent-to-agent interactions become more popular, we will stop looking at sessions as short-lived (as they are in the human-to-agent chat apps today). Instead, they will have durations more like email exchanges, which may last months or longer, but be intermittent. Building with an asynchronous mode just makes more sense.
But there is another option that works really well if the task at hand will take the server agent longer than a couple of minutes. And that’s the push notification method. For example, generating videos or large images may take a non-trivial amount of time. And, again, if this agent-to-agent thing really takes off, it may take a long time for the server agent to find and talk to other agents that will help it complete its task. In these cases, supplying a callback webhook means the client- and server-side agents can disconnect (and free up network resources) while the server-side agents continues to work. Then the server-side agent can inform the client via webhook that the result is ready.
Now that we have a solid understanding of how A2A works, let’s take a look at an example.
The Virtual Ethicist Code
Our agent will take a situation and provide a recommended action based on one of a few prominent moral philosophies. We’ll be using Gemini’s reasoning LLM, and here is the prompt we will send it:
You are a utilitarian moral philosopher. Announce which moral framework you are using, and then answer the question.
We’ll be writing the agent as a Spin app. To get going, we’ll use spin new and then immediately do a spin build to fetch all the necessary dependencies and get us started. The entire code can be found here in GitHub.
Now we can edit the src/index.ts file. We’ll focus on just two key functions.
taskUtilitarian is the main task for our agentdoGeminiInference fulfills the task using Google’s Gemini
// The main task handler for each request
async function taskUtilitarian(id: string, params: any): Promise<Response> {
// Get the question from the client's request
let question = params.message.parts[0].text;
// Create a task object that returns a one-shot inference
let task = new Task();
task.id = id;
task.sessionId = generateSessionId();
task.status = new TaskStatus();
task.status.state = "completed";
task.status.message = {
role: "agent",
parts: [
{
type: "text",
// Ask the question to Gemini and wait for the answer
text: await doGeminiInference(question),
},
],
};
// Build the JSON-RPC response envelope
let envelope = {
jsonrpc: "2.0",
id: id,
result: task,
};
// Send the entire response back to the client
let res = new Response(JSON.stringify(envelope));
res.headers.set("content-type", "application/json");
return res;
}
// Helper that uses Google Gemini to do the inference
async function doGeminiInference(question: string): Promise<string> {
let inference = await gemini.models.generateContent({
model: "gemini-2.0-flash",
contents: `You are a utilitarian moral philosopher. Announce which moral framework you are using, and then answer the question.
${question}`,
});
return Promise.resolve(inference.text || "Some philosophers choose silence.");
}
The snippet above shows the main agent, which runs a task on behalf of the client and then returns the result. We’re using the Gemini 2.0 Flash model, which is fast and efficient, and does a good job of handling this type of request.
One really cool thing about A2A is that the details of how we do the inference are opaque to the end user. If we discovered that, say, LLaMa did a better job of answering ethical questions, we could swap all of this out without so much as inconveniencing clients. In a sense, this is part of what makes A2A a compelling technology: One agent can learn how to interact with another agent, but without needing detailed information about how that agent is getting its work done.
Where Should Agents Run?
The agent we built above is a Spin app. Spin applications can run in a variety of locations, from your local system to Kubernetes clusters to the Akamai edge. What makes the most sense?
- If the results are cacheable, then put the application on the edge, as that will ensure that the agent runs as close as possible to the requesting client (be it another agent or a human).
- If you are running your own models, run the app as close to your GPUs as possible. So, for example, if you are using Civo GPUs to host a model, run the code in Civo’s cloud. (And if you are running edge GPUs, like with Akamai Cloud GPUs, this gives you the edge advantage even for self-hosted models)
- If you are using an AI service like Google Gemini, running as close to the user is likely a good move, since that will make use of the nearest GPU to the client. So once again, running at edge is best.
For the Gemini-based example above, I deployed to an Akamai endpoint, and then used Google’s demo A2A client to connect. Here’s what it looks like in action:
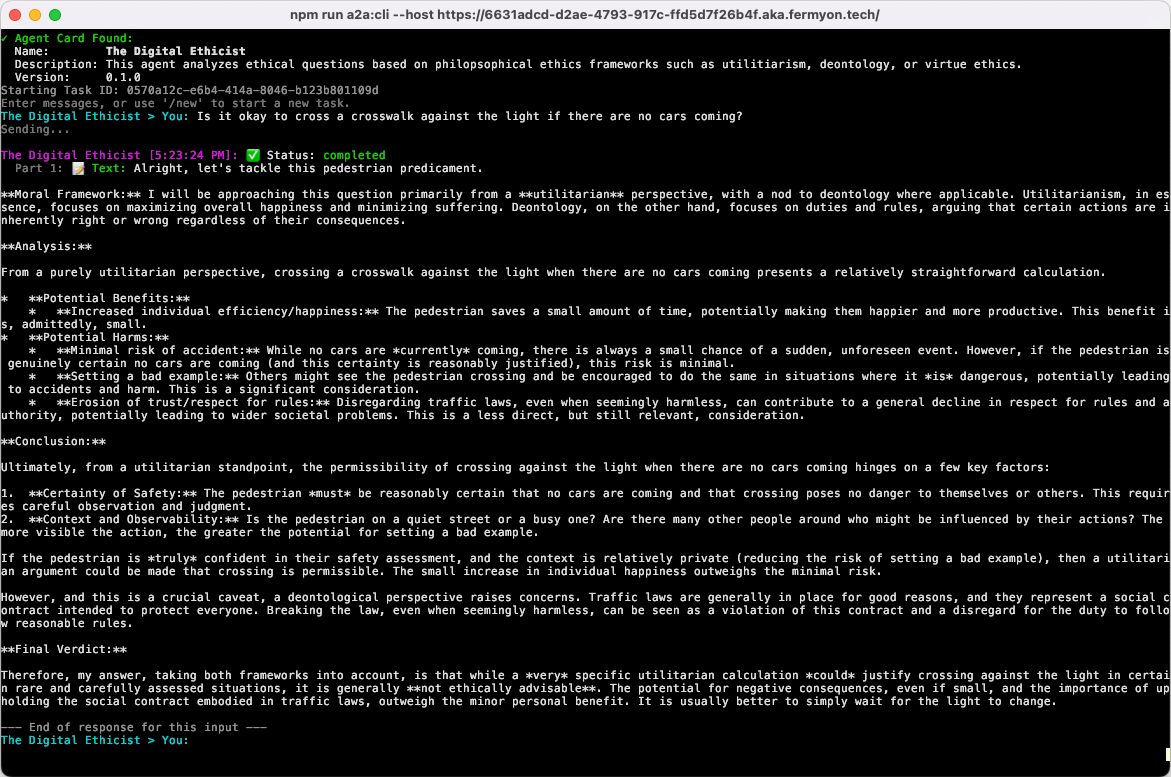
The response from the agent is detailed, providing a reason and then a “final verdict” for the prescribed action.
Conclusion
MCP is a protocol for exposing tools to agents. But A2A is different. Its purpose is to standardize a way for one agent to call to another agent. That requires two basic features: The ability to discover other agents, and the ability to interact with discovered agents. In A2A, the first is provided by JSON files in a simple agent card format. The second is provided via the existing JSON-RPC specification plus a few refinements for handling the longer interactions required by AI processing.
A2A is still lifting off, and it may be a little while before we see agents actually discovering and making use of other agents. But the foundation for this kind of interaction is laid by this new specification.